
Towards a Methodology for Experimental Evaluation in Low
Background
repeatable, reproducible, and comparable还没实现
低功耗无线的基准测试提高研究成果的重现性和可比性
解决问题的6个部分:
1.描述无线网络实验测试混杂的通用框架
2.一种成熟的实验方法,规定了如何计划、执行和报告实验结果
3.在低功耗无线网络环境下对可重复性、可复制性和可重复性的正式定义
4.比较方法
5.基准测试问题
6.技术解决方案
Contribution
我们概述了一种完善的方法,专门描述了如何进行实验评估,以及如何报告结果
本文主要针对2,3进行介绍并通过实验讲解
实验方法应用一个实验,报告了在相同测试配置下评估7个低功耗无线协议的性能
通过对相同的实验进行更多的重复,我们增加了在进行多次重复实验时所观察到的经验分布与真实总体分布紧密匹配的可信度
提高研究贡献的可重复性和可比性需要完善的实验方法:
1.The experiments
2.The analysis
3.The synthesis
Which metrics should be computed?
考虑实际情况,使用基于样本均值和样本标注差进行比较是不合适的,建议使用中位数或其他百分数方法,性能报告必须基于相同的度量标准才能进行比较。
Which raw data should be collected?
最低的要求是收集的数据能够很好地计算感兴趣的值。此外,数据度越大或未经处理的越多,越有价值。
How many samples should be collected?
一个人必须收集的样本的最小数量取决于兴趣的个数
How to synthesize results into a performance report?
性能指标,所有测试的中位数可以用来报告平均性能;需要更高的百分比来研究极端性能
How many experiments should be performed?
取决于性能指标类型
Conclusion:
1,每次实验采用相同的标准,这个标准要获得权威性
2,数据应该深度分析
3,预测方法应基于某些分布百分位数的置信区间
4,性能报告应使用CIs进行综合,最低可信度75%,更好是95%,不使用平均值和方差
5,进行多次小测试,而不是整体测试
实验:
1,测试场景
布15个点,14个源节点,一个sink节点
每个源节点每秒生成10个数据,要生成200个2字节的数据,
开始的第一个10秒没有产生数据,之后周期性产生数据,在不同的源之间存在伪随机偏移,
一旦产生200个数据,再运行10秒后停止,此时在sink节点上未成功接收到的任何应用程序数据都将被视为丢失,这与以估计稳态性能为目标的测试场景不同。在运行场景之后,可以获得准确的性能度量,而不是评估。不确定性在于多次运行的结果的可变性,而不是如果测试更长时可获得的性能
2,测试环境
使用FlockLab testbed作为测试环境,使用DPP平台(TI CC430)
知道节点列表和sink节点的标识
测试时间在夜间(晚上10点到早上7点)进行,以限制外部干扰。
###3,性能指标,测量和综合方法
使用本论文方法,在选择有效的措施和综合策略之前,首先确定评估目标和性能指标
比如研究一下几个方面:
1,在场景的一次执行中,您可以成功接收多少有效应用数据?
这涉及到平均可靠性,在测量PRR,选取95%时的CI下限为可靠性的均值
2,在场景的一次执行过程中,一个节点可以消耗多少能量?
这涉及所有节点的平均能量消耗,我们使用95%CI的上限为能量消耗的均值
3,在测试了多少次之后,第一个源节点的电量将耗尽
这涉及每个源节点的最大能源消耗
我们使用三个标准化绩效指标综合评估结果。通过设计,PRR已经标准化,对于能量消耗,标准值y=1-x/I_max,x为测量值,I_max=25mA是上限。因此,我们的三个性能指标在0到1之间,得分越高,性能越好。
4,实验的长度和次数
因为实验一直运行到结束,所以实验长度是开始到结束 措施和策略取决于95%的中值CI,所以,测量至少6次。为了获得更高的评估,测量了20次,如果20次都是有效的,那么95%的CI中值是[x_6 x_15].
5,原始数据收集
原始数据应提供足够的信息来计算感兴趣的指标,但也应尽可能详细,以便可以进一步或不同的处理,基于此收集数据如下:
sink节点将单个接收到的应用程序有效数据(2个伪随机字节)写入一个串行消息,串行转储由FlockLab提供,作为测试结果的一部分
FlockLab以每秒144000个样本(每~7μs一个样本)的速率收集每个节点的电流消耗测量值,精度为10pA,
对于每个节点,测试结果包含完整的时间序列和整个测试的平均值. 最后将这些原始数据转换为性能指标。
6,评估结果
评估之后的问题是如何呈现结果。在这方面,挑战在于以简洁但信息量大的形式报告结果。评介结果使用简洁而包含足够多的信息的形式展现,一定要有一些有代表性的数据。
对于一些指标,图形表示可以快速概述不同协议的各自性能,
不过,数据表更精确,应该提供。
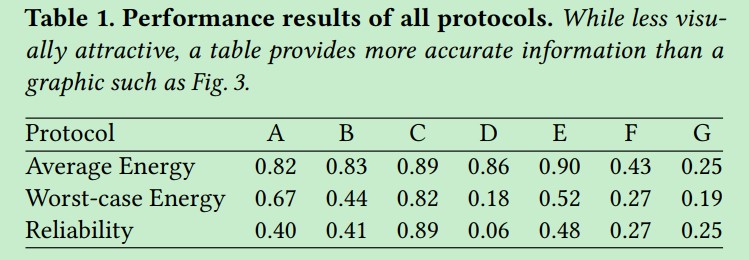
此外,只要相关,就应该提供所有处理数据的某种表示
这样的图表简洁地显示了数据点、它们的分布和它们的合成;因此,它提供了关于给定协议性能的更多细节,而不仅仅是性能指标。


1.重复性(Repeatability ):当同一零件的同一种特征由同一个人进行多次测量时变异的总和。
说明:其实验数据必须符合以下条件:同一人员、同一产品、同一环境、同一位置、同一仪器、短期时间内.
2.再现性(Reproducibility ):当同一零件的同一种特征由不同的人使用同一量具进行测量时,在测量平均值方面的变异的总和。
说明:其实验数据必须符合以下条件: 不同人员同一产品、不同环境、不同位置、不同仪器、较长时间段.
再现无线低功耗网络 无线低功耗网络的环境是多变的,所以考虑测试结果完全一样没有意义,我们应该考虑相似就可以了,但是如何去衡量相似性,什么样的结果是相似的呢?可复制性是否有意义,还是说专注再现性?
让我们专注重复性

根据ACM定义,如果我们得到整个测试结果,我们会发现相似性,换句话说,重复性与评价结果的可信度有关
关于这个问题,可以采用Bootstrapping,Bootstrapping是一种基于重新抽样的统计方法,它可以提高某些总体估计的准确性。假设我们执行一个N次重复的评估,从中计算一个性能指标向量。bootstrap样本是指一个新的合成的N个测试集,其中bootstrap样本中的每个测试都是从原来的N个测试中随机选择的。例如,原本的集合是{1,2,3},bootstrap样本被随机创建为{2,1,2},对于每个bootstrap样本,我们可以计算一个新的绩效指标向量。通过创建很多bootstrap样本,我们很容易从原来的N个测试中得到性能向量的总体。这看着是凭空创造的,但是给出了对某些总体参数的置信区间;在我们的例子中,这个参数是性能指标的向量。这个方法被用在人口分布的结果重复性中。性能向量与bootstrap分布越接近,结果就越“可重复”。
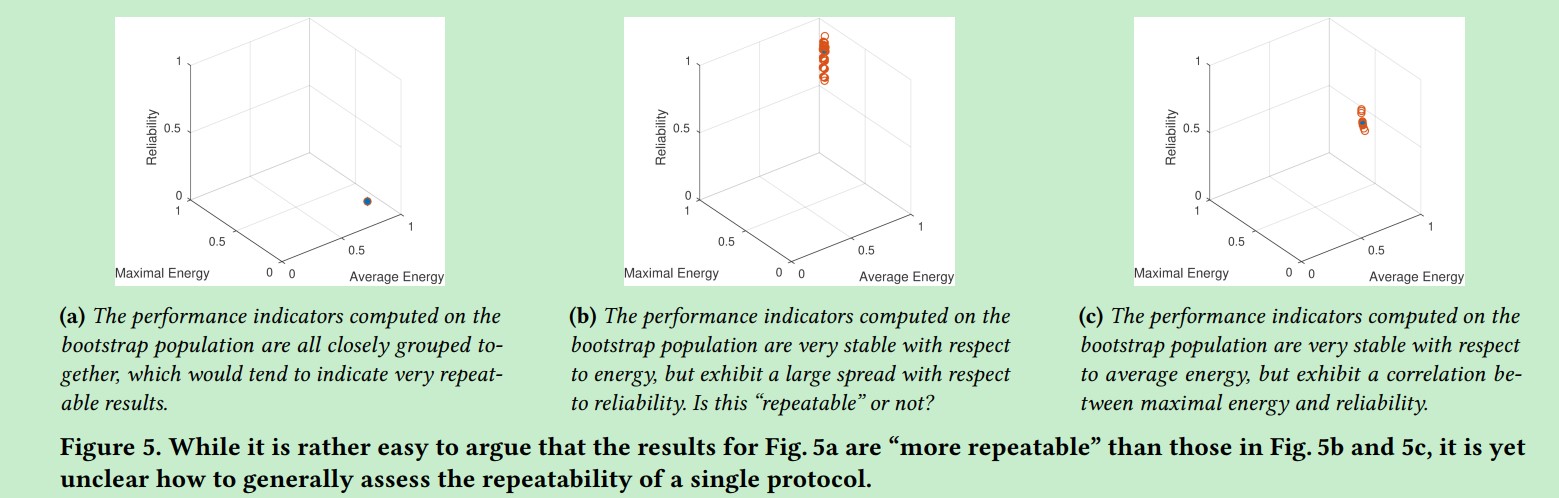
很明显,第一个图比第2,3图更具有可重复性。我们不知道单个指标是否具有可重复性,此外,还要注意bootstrap是否适用我们的指标。但是这个问题还是有研究的价值。
未来规划
1,未来是找到完整,成熟的评价方法, 作为一个公认的准则,在现场实验评估。
2,原始实验和平行性/再现性实现之间的“密切关系”可以用下列问题来表示:两组结果样本来自相同基础分布的概率是多少?
总结与讨论
1,在这篇文章中,我们概述了一些必要的步骤,使实验研究的低功耗无线网络可重复性,重复性,可比性。
2,我们发现缺乏一种完善的方法来指定如何计划、执行和报告实验结果,这是实现这一目标所缺少的要素之一。因此,我们提出了一种适用于低功耗无线协议实验的方法,并将其应用于一个案例研究。
3,我们还进一步讨论了在低功耗无线网络环境下防御可重复性、可复制性和可再现性的复杂性。
Paper
Paper �Paper Pages
<hr style="visibility: hidden;"/>
<link rel="stylesheet" href="https://unpkg.com/gitalk/dist/gitalk.css"/>
<script src="https://unpkg.com/gitalk@latest/dist/gitalk.min.js"></script>
<div id="gitalk-container"></div>
<script src="/js/md5.min.js"></script>
<script type="text/javascript">
var gitalk = new Gitalk({
clientID: 'bac30f359de5d507a610',
clientSecret: '8d1731513ae0df821226384107ae088b73e1e329',
repo: 'a416485164.github.io',
owner: 'a416485164',
admin: ['a416485164'],
distractionFreeMode: true,
id: md5(location.pathname),
});
gitalk.render('gitalk-container');
</script>

