
An Empirical Evaluation of In
An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
引言
In-Memory的数据库也最近的一个研究的热点,此外,MVCC相对于其它存在的Concurrency Control方法,相对来说是最均衡的,新设计的In-Memory绝大部分采用的是MVCC的方法(OCC的缺点太明显了,write一多就abort)。基于MVCC的DBMS允许一个只读事务在读取一个较老版本的同时另外一个事务更新相同的一个对象,能获取更加好的并发程度。此外,如果DBMS没有移除对象的就版本,这个系统就可以支持读取过去一个时间点的快照。虽然有诸多的DBMS使用了MVCC,但是它们之间的MVCC的方式很多不同的地方。这篇论文主要分析不同MVCC在这些方面方面上的一个特点:
1. 并发控制协议;
2. 版本存储;
3. 垃圾回收;
4. 索引管理。
(更新)强烈推荐的一片论文。
MVCC Overview
表1给出了常见数据4个方面的对比:
忽略其一些具体实现的差异,一个基于MVCC的DBMS一般有相同的一些用于事务和数据元组的元数据: Transactions: DBMS会赋予一个事务一个递增的时间戳作为事务id,用于表示这个事务。并发控制协议使用这个标识符标识一个事务可以访问的元组。Tuples: 一个物理上的版本的数据包含了4个元数据字段(具体的可能有些区别),如下图所示:
+--------+-----------+---------+---------+------+-------------------------------+
| | | | | | |
| txn-id | begain-ts | end-ts | pointer | ... | cloumns... |
| | | | | | |
+--------+-----------+---------+---------+------+-------------------------------+
+ + +
| <---------------- Header -----------------> | <--------- Content ---------> |
+ + +
txn-id字段作为这个版本的写锁,当一个元组没有被上写锁的时候,这个字段就是0。大部分的DBMS使用一个64bit的整形作为txn-id,这样就是可以使用一个CAS就可以原子地更新txn-id的值。如果一个事务T(事务id为T(id)),想要更新这个元组,它会先检查txn-id的值,如果是0,那么它就会使用CAS操作将txn-id设置为T(id)。当一个事务尝试更新一个txn-id字段不为0且不等于自身T(id)的时候,这个事务就是abort。Begain-ts和end-ts代表了这个元组的生存期,都被初始化为0,将begain-ts设置为INF代表一个事务将其删除。最后的pointer字段保存了相邻的的版本的地址。
Concurrency Control Protocol
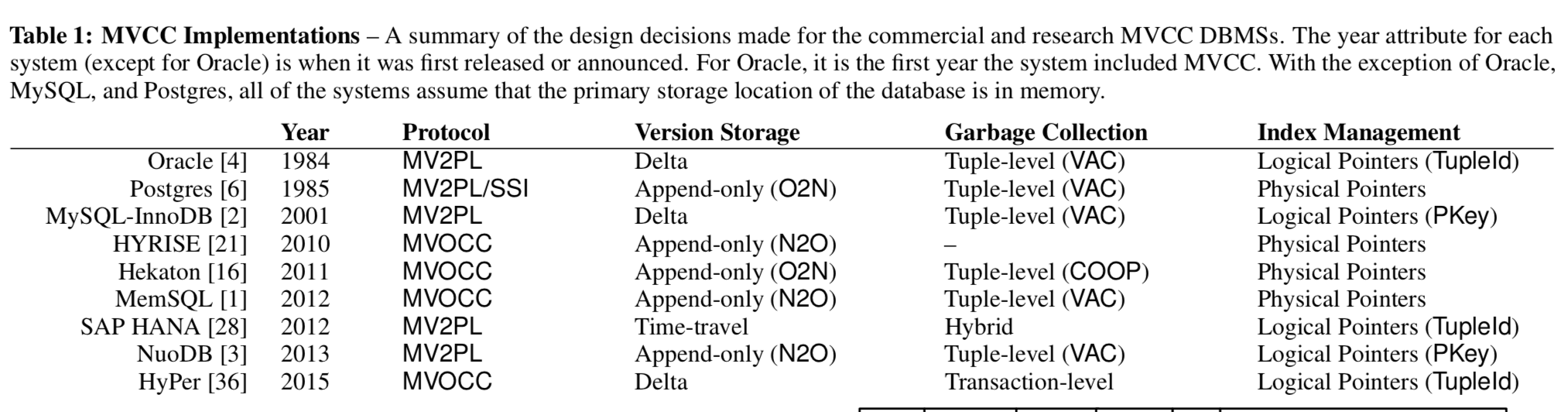
Timestamp Ordering (MVTO)
MVTO是最初的MVCC的Concurrency Control Protocol(CCP),tuple的header中还保存了最近的事务读取它的时间。MVTO其基本思路就是使用tid提前计算它们序列化的顺序。当一个txn尝试读取or更新一个已经上了write lock的一个版本,这个txn就会abort。当一个txn准备读取一个tuple时,会根据begin-ts和end-ts和tid来找到具体要读取的tuple的版本。
上图中,tuple的txn-id为0 or这个txn自己的id时,代表没有被其它事务上write lock,可以正常操作。MVTO不允许读未提交,这里使用的方式就是一个txn读取一个tuple的时候,如何read-ts小于自己的tid,就将其设为tid,如果大于,则选择一个更旧的版本。MVTO中,txn总是更新最近的一个版本,当满足一个tuple: 1.没有其它事务获取了write lock,2.txn的tid大于tuple的read-ts,则可以更新一个新版本。在更新之后,tuple的txn-id设置为txn的tid,txn提交的时候,设置新的版本的begin-ts为tid,end-ts为无穷大,最近的一个旧的的版本的end-ts为txn的id。
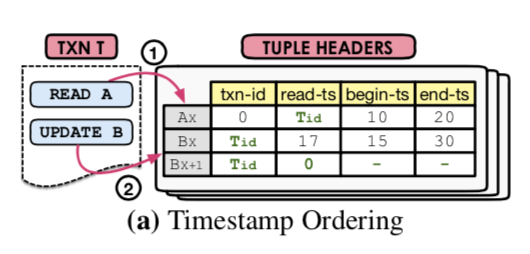
Optimistic Concurrency Control (MVOCC)
从上面的表中可以发现,使用MVOCC的基本时内存数据库。MVOCC结合了MVCC和OCC的一些特点。
This reduces the amount of time that a transaction holds locks. There are changes to the original OCC protocol to adapt it for multi-versioning [27]. Foremost is that the DBMS does not maintain a private workspace for transactions, since the tuples’ versioning information already prevents transactions from reading or updating versions that should not be visible to them.
MVOCC将txn分为3个阶段:
-
read phase,MVOCC通过begin-ts 和 end-ts 来决定一个一个tuple的可见性。
-
alidation phase,在这个阶段,数据库会赋予txn一个时间差,叫做t-commit,使用这个时间戳来检查这个事务read-set中哪些tuples被提交更新了。
-
write phase ,如果第2步通过,进入第3步,更新一个新版本的数据,begin-ts设计为tid,end-ts设置为INF。
<div class="highlighter-rouge">Transactions can only update the latest version of a tuple. But a transaction cannot read a new version until the other transaction that created it commits. A transaction that reads an outdated version will only find out that it should abort in the validation phase.
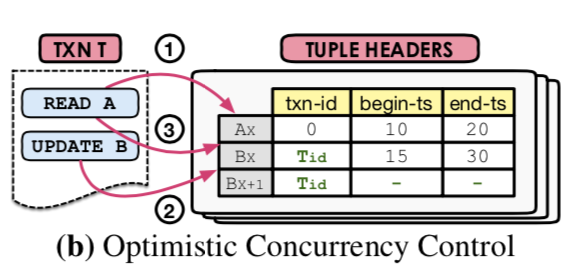
Two-phase Locking (MV2PL)
前面的表中,MV2PL最多被传统的数据库使用,使用2PL来实现serializability。txn读取or更新都需要加适当的lock,lock和tuple时分开的,lock不会被置换到磁盘上。tuple的lock就是tuple的txn-id字段,对于读锁,使用一个read-cnt字段来表示目前的reader的数量。txn使用tid和tuple的begain-ts字段决定一个tuple的可见性。只有在read-cnt和txn-id都为0的时候才能更新操作。当一个txn提交的时候,数据库赋予其一个唯一的t-commit时间戳来设置tuple的begin-ts字段,然后释放lock(s)。 这个版本的MVCC中,一个重要的问题就是如何避免deadlock。
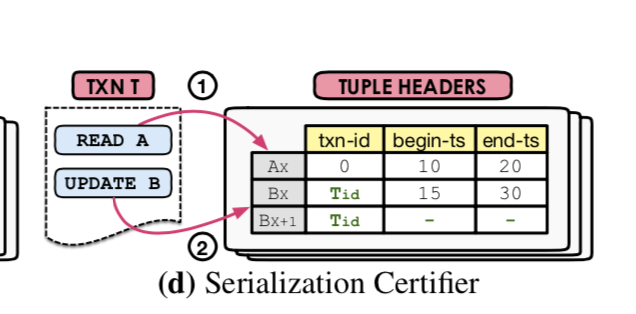
Serialization Certifier
最后一个protocol出现的目的时为了解决SI的isolation level不能完全满足serializability的要求,出现的时间也比较晚。MVCC能满足的隔离级别一般时SI,最大的一个问题就是write skew。常见的思路是维护一个serialization graph来检测可能导致write skew问题的情况,最近还出现了serial safety net不同于serialization graph的方法。这里涉及的比较多,可以参考相关论文。
Version Storage
MVCC每次更新都会产生一个tuple的新版本,如果将这些版本组织在一起呢?
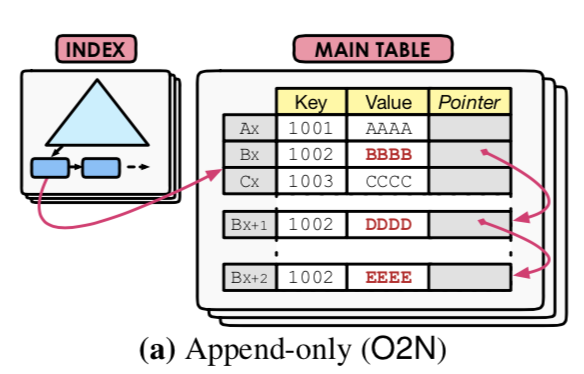
Oldest-to-Newest (O2N)
这个是Append-only Storage中的一种。不同的版本组织成list,最旧的版本在最前面。优点是添加新版本的时候不需要更新索引,缺点就是要查找合适的版本的时候可能要搜索较长的链。
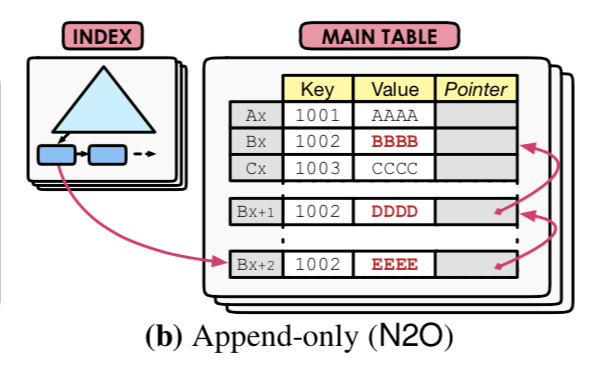
Newest-to-Oldest (N2O)
和上面的一个一样,这个也是Append-only Storage中的一种。不同的在于新的版本在最前面,旧的在后面。优缺点也和上面的想法,大部分的txn都是访问最新的版本,所以直接找第1个版本的数据就可以了,缺点就是添加版本的时候需要更新索引。一个解决更新索引问题的办法就是使用一个间接层(又是添加间接层)。
Append-only Storage存在的另外一个问题就是对于非内联的字段,直接拷贝的话可能造成不必要的overhead。可以使用的解决办法就是允许不同版本的tuple保存指向同一个非内联字段的指针。对于这些字段,则需要保存一个ref count。
Time-Travel Storage
在这种方式中,DB保存一个master版本在一个main table中,然后在time-travel table中保存其它的版本,这些版本直接也组织成list。在main table中的版本不一定就是当前的版本。对于将当前版本保存在main table里面的,更新的时候需要在time-travel table里面申请一个新的空间,将main table里面的版本拷贝过去,然后在main table 里面更新新的版本。
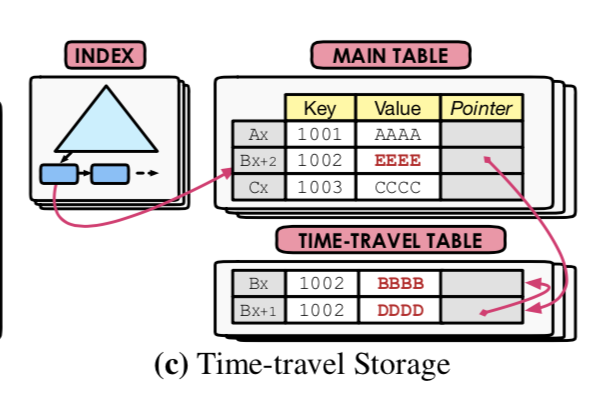
这种方式也同样存在上面提到非内联的字段的问题,解决方案也一样。
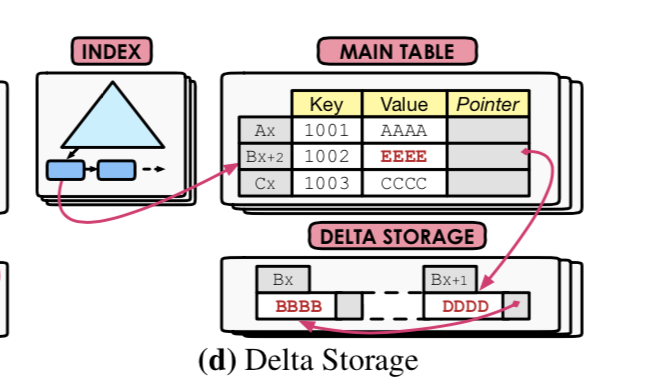
Delta Storage
这种方式是两大最常用的数据库Oracle 和 MySQL(InnoDB)使用的方法。大部分都是在main table中保存当前的版本,然后在一个与main table分离的地方保存delta数据。 delta,顾名思义,就是只会保存更新记录的部分。这种方式的优点在与更新的时候不需要完全新建立一个tuple,缺点就是对于读密集的常见可能造成比较高的overhead,因为每次都要处理delta。
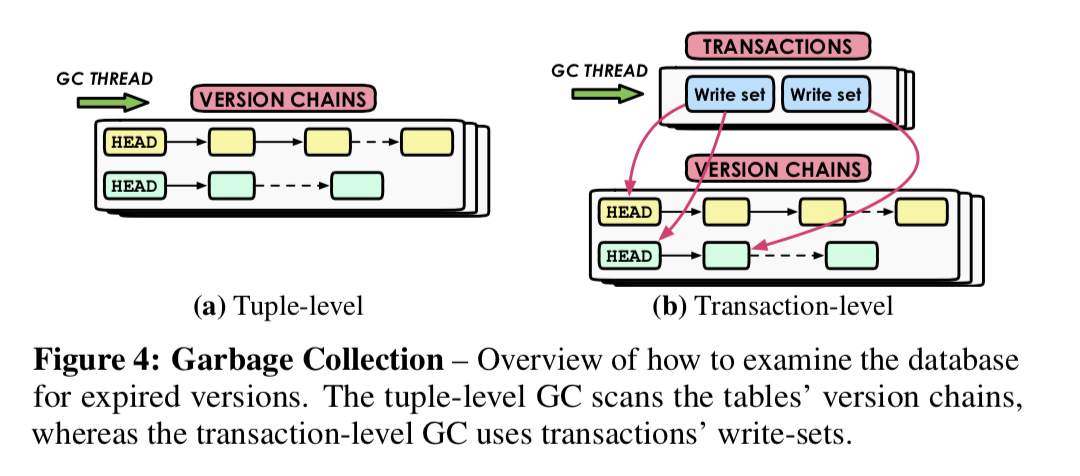
Garbage Collection
MVCC的更新方式就会使得系统产生很多的(过了一段时间之后就)不需要的数据,回收这些有GC模块进行。一般而言,这部分的工作都是分为3步:
- 探明过期的数据;
- 将这个版本的数据从tm的list和indexs中剥离;
- 回收;这里的第一个问题就是如何确定一个版本的数据已经过期了,这里的一个部分就是:如何数据是由abort了的txn产生的,那么这些数据就是无效的,or 如果这个数据的end-ts比现在的最小的txn的tid还要小,那么这个数据也是过期的。对于内存数据库了,很多使用了机遇epoch的内存回收方式。
Background Vacuuming (VAC)
VAC是Tuple-level Garbage Collection的一种。在这种方法中,DB使用后台threads,周期性的扫描过期的tuples。
...transactions register the invalidated versions in a latch-free data structure. The GC threads then reclaim these expired versions using the epoch-based scheme described above. Another optimization is where the DBMS maintains a bitmap of dirty blocks so that the vacuum threads do not examine blocks that were not modified since the last GC pass.
Cooperative Cleaning (COOP)
这种方式也是Tuple-level Garbage Collection的一种,一个txn在执行的时候,将发现的过期的tuples记录在一个全局的结构之中,这样对于GC thread来说,它们就不需要主动去探测过期的数据了。不过一个缺点就是只适合O2N append-only storage 的模式。
One additional challenge is that if transactions do not traverse a version chain for a particular tuple, then the system will never remove its expired versions. This problem is called “dusty corners” in Hekaton. The DBMS overcomes this by periodically performing a complete GC pass with a separate thread like in VAC.
Transaction-level Garbage Collection
Transaction-level的GC以Transaction为粒度,和上面所有的存储方式都兼容。当一个txn产生的数据被所有的txn不可见是,DB认为这些数据就是过期的了。
After an epoch ends, all of the versions that were generated by the transactions belonging to that epoch can be safely removed. This is simpler than the tuple-level GC scheme, and thus it works well with the transaction-local storage optimization.
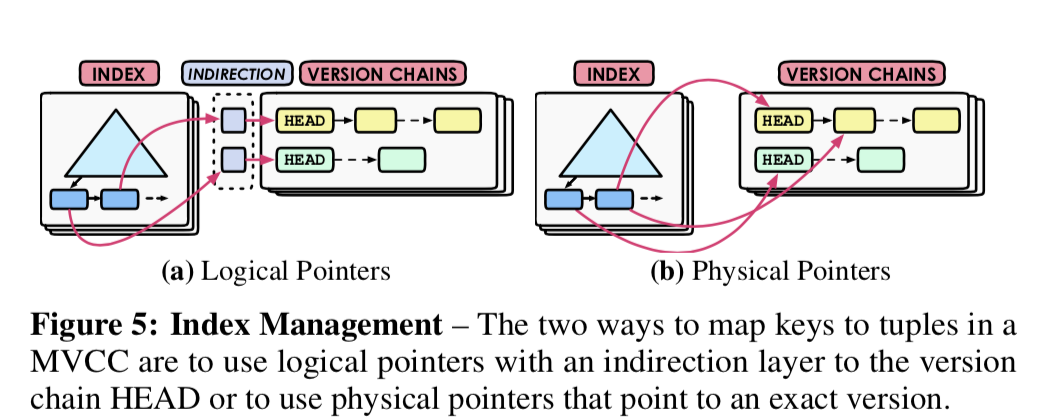
Index Management
Index Management值得是如何组织index和tuple直接的联系,可以通过index找到对应的tuple。所有的MVCC的实现都将index和版本的信息分离开。主键的index总是指向目前tuple的版本。如果更新主键index和tuple直接的联系就和具体的实现相关。上面提到过,Oracle MySQL使用的delta的方式,主键就中是直达master记录;对于append only的方式, N2O就要求在tuple更新的时候也更新index。对于次级index,情况更加复杂。这里主要有两种类型的方式,第一种就是使用逻辑指针,第二种就是使用物理指针。
Primary Key (PKey)
PKey是逻辑指针的一种,次级索引的key可以理解为就是主键,从次级index查找是,要先找到主键,如何从主键index中执行另外一次查找,找到对应的数据。
If a secondary index’s attributes overlap with the primary key, then the DBMS does not have to store the entire primary key in each entry.
Tuple Id (TupleId)
上面一种方式的缺点就是可能会占用比较大的空间,因为将主键保存了很多次。这里的一个解决办法就是保存一个tuple-id,这个id一般是DB内部管理的,一般为一个64bit的整数。
An alternative is to use a unique 64-bit tuple identifier instead of the primary key and a separate latch-free hash table to maintain the mapping information to the tuple’s version chain HEAD.
Physical Pointers
处理逻辑指针,还可以直接就保存指向tuple的物理指针。不过这种方式只适用于append only的模式,因为DB将这些数据保存在同一个table中,所有的index都可以指向它们。更新的时候,则需要更新所有的idnex。
In this manner, the DBMS can search for a tuple from a secondary index without comparing the secondary key with all of the indexed versions. Several MVCC DBMSs, including MemSQL and Hekaton, employ this scheme.
评估与论述
参考论文[1].
参考
- An Empirical Evaluation of In-Memory Multi-Version Concurrency Control, VLDB 2017.
- H. Berenson and et al. A Critique of ANSI SQL Isolation Levels. SIGMOD’95.

