
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
目录:
基础知识
对于大多数深入学习的实践者来说,序列建模是循环网络的同义词。然而,最近的研究结果表明,卷积结构在音频合成和机器翻译等任务上可以优于循环网络。给定一个新的序列建模任务或数据集,应该使用哪个体系结构?作者对用于序列建模的通用卷积和循环体系结构进行了系统评估。实验表明,一个简单的卷积结构在不同的任务和数据集范围内都优于典型的循环网络(如LSTM),同时显示出更长的有效记忆。
TCN的特点:
- 使用了因果卷积,意味着未来到过去没有信息泄露
- 该结构将任意长度的输入序列映射到相同长度的输出序列(和RNN一样)
- 使用残差网络和扩展卷积的组合来增强网络记忆。
1. 时间序列
序列模型
假设给定一个序列 ${x_0, x_1, … , x_T}$,我们希望预测每一时刻对应的输出 ${y_0, y_1, …, y_T}$。序列模型网络是任意函数 $f:x^{T+1} -> y^{T+1}$ 产生的映射。$ hat{y_0}, …, hat{y_0} = f(x_0, … , x_T)$ ,其中 $ hat y $ 是真实的对应值。它应该满足因果约束:$y_t$ 仅仅依赖于 ${x_0, x_1, … , x_t}$,而不依赖于 ${x_{t+1}, … , x_T}$。在序列模型中,学习的目标是找到一个网络 f,最小化实际输出和预测之间的损失函数 [ L(y_0, y_1, …, y_T, f(x_0, … , x_T)) ] 其中序列和输出是根据分布描绘的。
在进行语音识别时,给定了一个输入音频片段 X ,并要求输出对应的文字记录 Y 。这个例子里输入和输出数据都是序列模型,因为 X 是一个按时播放的音频片段,输出 Y 是一系列单词。
音乐生成问题是使用序列数据的另一个例子,只有输出数据 Y 是序列,而输入数据可以是空集,也可以是个单一的整数,这个数可能指代你想要生成的音乐风格,也可能是你想要生成的那首曲子的头几个音符。输入的 X 可以是空的,或者就是个数字,然后输出序列 Y 。
在处理文本时,输入的文本也是序列。
2. RNN, LSTM, GRU
RNN
核心是每个输入对应隐层节点,而隐层节点之间形成了线性序列,信息由前向后在隐层之间逐步向后传递。
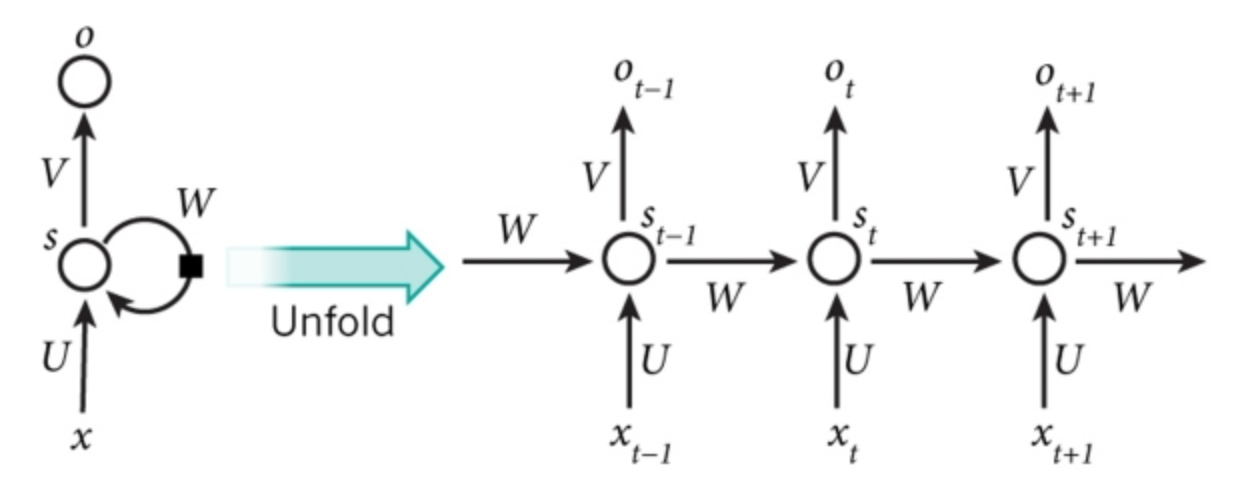 图显示的是RNN模型全部展开时的情况。“展开”指的是用网络描述出所有序列。
RNN(循环神经网络)之所以是“循环”,是因为它们对序列的每个元素执行相同的任务,而每次的结果都独立于之前的计算。理论上讲,RNN可以利用任意长度的序列信息,但只可以利用有限的前几步的信息。
例如,如果序列中的句子有5个单词,那么,横向展开网络后将有五层神经网络,一层对应一个单词。
下面解释一下其中的计算公式:
$x_t$ 是在时刻t时的输入。例如,$x_1$ 对应于一个句子的第二个词的实数向量
$s_t$是在时刻 $t$ 时的隐藏状态,类似于网络的“大脑”,也就是“记忆模块”的值
$s_t$的运算是基于以前隐藏状态 $s_{t-1}$ 和当前的输入 $x_t$ 决定的,其中激活函数通常是非线性的,例如,
图显示的是RNN模型全部展开时的情况。“展开”指的是用网络描述出所有序列。
RNN(循环神经网络)之所以是“循环”,是因为它们对序列的每个元素执行相同的任务,而每次的结果都独立于之前的计算。理论上讲,RNN可以利用任意长度的序列信息,但只可以利用有限的前几步的信息。
例如,如果序列中的句子有5个单词,那么,横向展开网络后将有五层神经网络,一层对应一个单词。
下面解释一下其中的计算公式:
$x_t$ 是在时刻t时的输入。例如,$x_1$ 对应于一个句子的第二个词的实数向量
$s_t$是在时刻 $t$ 时的隐藏状态,类似于网络的“大脑”,也就是“记忆模块”的值
$s_t$的运算是基于以前隐藏状态 $s_{t-1}$ 和当前的输入 $x_t$ 决定的,其中激活函数通常是非线性的,例如,tanh or ReLU 函数。
$o_t$是时刻 $t$ 时的输出结果。如,预推测句子中的下一个词,那么在这里的输出就可以表示为一个词典序列,值为每一个词的概率。
LSTM
原始的RNN也存在问题,它采取线性序列结构不断从前往后收集输入信息,但这种线性序列结构在反向传播的时候存在优化困难问题,因为反向传播路径太长,容易导致严重的梯度消失或梯度爆炸问题。为了解决这个问题,后来引入了LSTM和GRU模型,通过增加中间状态信息直接向后传播,以此缓解梯度消失问题,获得了很好的效果,于是很快LSTM和GRU成为RNN的标准模型。
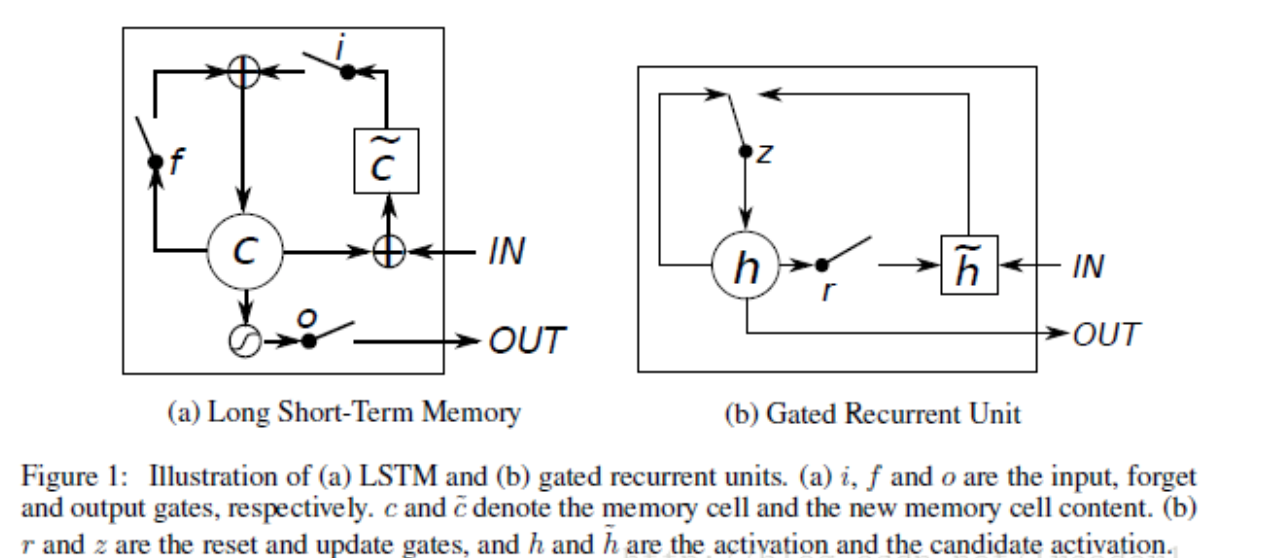
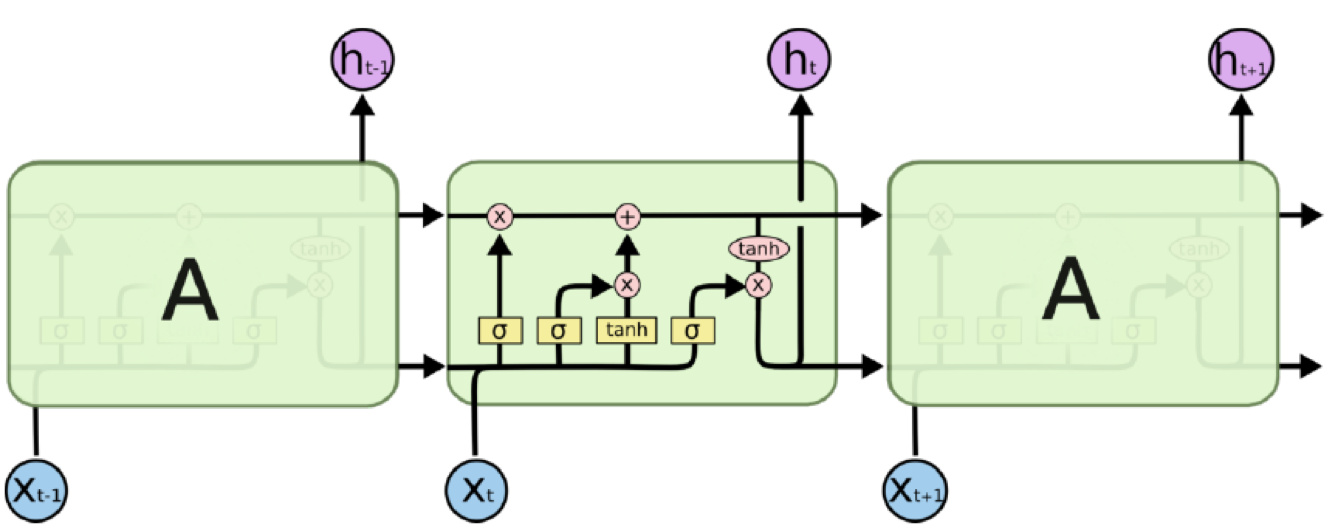 LSTM 里面最重要的概念是“门结构(gate)”,分为遗忘门,输入门和输出门。
LSTM 里面最重要的概念是“门结构(gate)”,分为遗忘门,输入门和输出门。
GRU
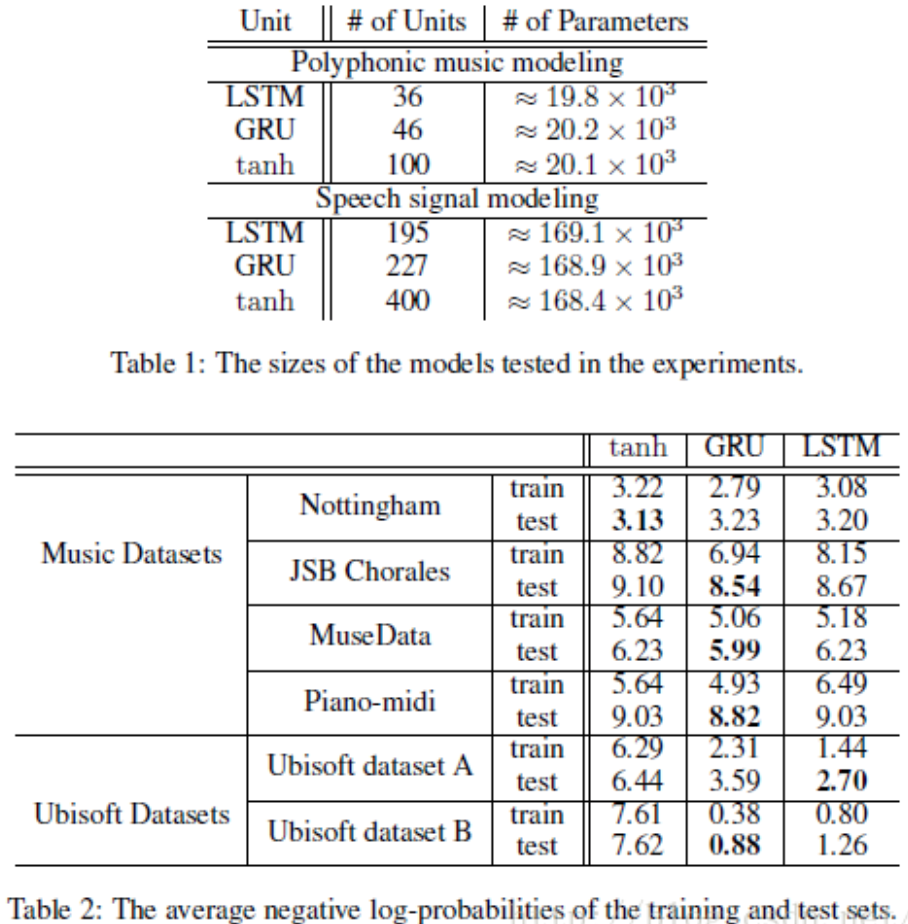
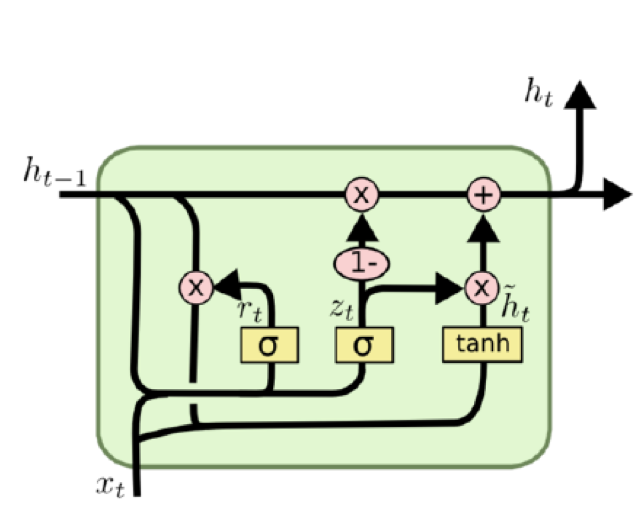 将遗忘门和输入门合成了一个单一的重置门(reset gate),也就是说多大程度上擦除以前的状态state,另外细胞更新操作变为更新门(update gete),它的作用是多大程度上要用candidate 来更新当前的hidden layer。
将遗忘门和输入门合成了一个单一的重置门(reset gate),也就是说多大程度上擦除以前的状态state,另外细胞更新操作变为更新门(update gete),它的作用是多大程度上要用candidate 来更新当前的hidden layer。
LSTM和GRU对比
标准LSTM和GRU的差别并不大,但是都比tanh要明显好很多,所以在选择标准LSTM或者GRU的时候还要看具体的任务是什么。 使用LSTM的原因之一是解决RNN Deep Network的Gradient错误累积太多,以至于Gradient归零或者成为无穷大,所以无法继续进行优化的问题。GRU的构造更简单:比LSTM少一个gate,这样就少几个矩阵乘法。在训练数据很大的情况下GRU能节省很多时间。因为gru参数更少,所以gru训练起来比lstm更简单。
缺点:
经过特殊改造的CNN模型,以及最近特别流行的Transformer,这些后起之秀尤其是Transformer的应用效果相比RNN来说,目前看具有明显的优势。
RNN本身的序列依赖结构对于大规模并行计算来说是个问题,这个问题严重阻碍了RNN的发展。原因:因为T时刻的计算依赖T-1时刻的隐层计算结果,而T-1时刻的计算依赖T-2时刻的隐层计算结果……..这样就形成了所谓的序列依赖关系。就是说只能先把第1时间步的算完,才能算第2时间步的结果,这就造成了RNN在这个角度上是无法并行计算的,只能老老实实地按着时间步一个单词一个单词往后走。
3. CNN
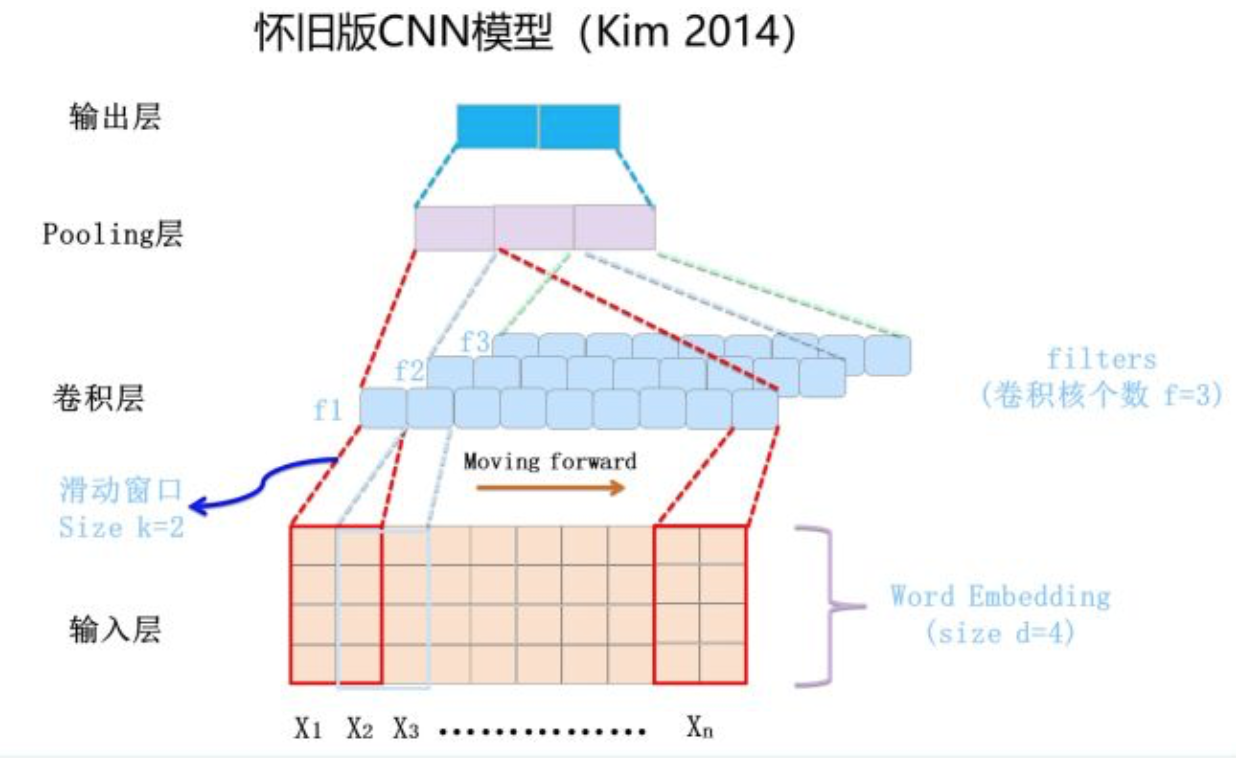
一般而言,输入的字或者词用 Word Embedding 的方式表达,这样本来一维的文本信息输入就转换成了二维的输入结构,假设输入X包含n个字符,而每个字符的 Word Embedding 的长度为d,那么输入就是 d*n 的二维向量。
卷积层本质上是个特征抽取层,可以设定超参数F来指定卷积层包含多少个卷积核(Filter)。对于某个Filter来说,可以想象有一个d*k大小的移动窗口从输入矩阵的第一个字开始不断往后移动,其中k是 Filter 指定的窗口大小,d 是 Word Embedding 长度。对于某个时刻的窗口,通过神经网络的非线性变换,将这个窗口内的输入值转换为某个特征值,随着窗口不断往后移动,这个Filter对应的特征值不断产生,形成这个Filter的特征向量。这就是卷积核抽取特征的过程。卷积层内每个Filter都如此操作,就形成了不同的特征序列。Pooling 层则对Filter的特征进行降维操作,形成最终的特征。一般在 Pooling 层之后连接全联接层神经网络,形成最后的分类过程。
这就是最早应用在 NLP 领域 CNN 模型的工作机制,用来解决 NLP 中的句子分类任务,看起来还是很简洁的,之后陆续出现了在此基础上的改进模型。这些怀旧版 CNN 模型在一些任务上也能和当时怀旧版本的RNN模型效果相当,所以在 NLP 若干领域也能野蛮生长,但是在更多的NLP领域,还是处于被RNN模型压制到抑郁症早期的尴尬局面。
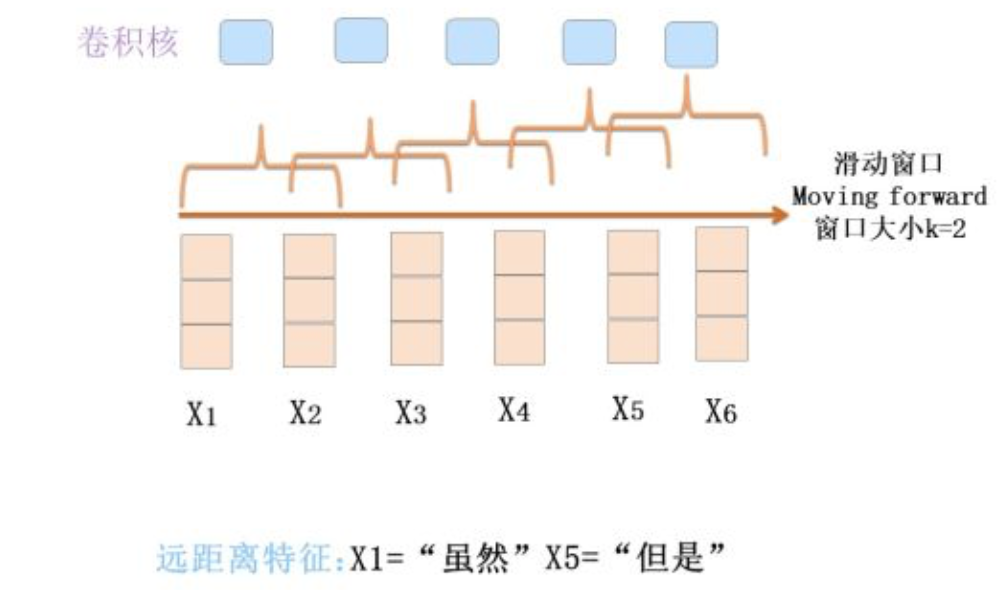
CNN 捕获到的是什么特征呢?从上述怀旧版本 CNN 卷积层的运作机制你大概看出来了,关键在于卷积核覆盖的那个滑动窗口,CNN能捕获到的特征基本都体现在这个滑动窗口里了。大小为 k 的滑动窗口轻轻的穿过句子的一个个单词,荡起阵阵涟漪,那么它捕获了什么?其实它捕获到的是单词的 k-gram 片段信息,这些 k-gram 片段就是CNN捕获到的特征,k 的大小决定了能捕获多远距离的特征。
对于远距离特征,单层 CNN 是无法捕获到的,如果滑动窗口 k 最大为2,而如果有个远距离特征距离是5,那么无论上多少个卷积核,都无法覆盖到长度为5的距离的输入,所以它是无法捕获长距离特征的。
有两种典型的改进方法:
一种是假设我们仍然用单个卷积层,滑动窗口大小 k 假设为3,就是只接收三个输入单词,但是我们想捕获距离为5的特征,可以跳着覆盖呀?这就是 Dilated 卷积的基本思想。
第二种方法是把深度做起来。第一层卷积层,假设滑动窗口大小k是3,如果再往上叠一层卷积层,假设滑动窗口大小也是3,但是第二层窗口覆盖的是第一层窗口的输出特征,所以它其实能覆盖输入的距离达到了5。如果继续往上叠加卷积层,可以继续增大卷积核覆盖输入的长度。
Kim 版本 CNN 还有一个问题,就是那个 Max Pooling 层,这块其实与CNN 能否保持输入句子中单词的位置信息有关系。RNN因为是线性序列结构,所以很自然它天然就会把位置信息编码进去;那么,CNN 是否能够保留原始输入的相对位置信息呢?其实 CNN 的卷积核是能保留特征之间的相对位置的,道理很简单,滑动窗口从左到右滑动,捕获到的特征也是如此顺序排列,所以它在结构上已经记录了相对位置信息了。但是如果卷积层后面立即接上 Pooling 层的话,Max Pooling 的操作逻辑是:从一个卷积核获得的特征向量里只选中并保留最强的那一个特征,所以到了 Pooling 层,位置信息就被扔掉了,这在 NLP 里其实是有信息损失的。所以在 NLP 领域里,目前 CNN 的一个发展趋势是抛弃 Pooling 层,靠全卷积层来叠加网络深度,这背后是有原因的。
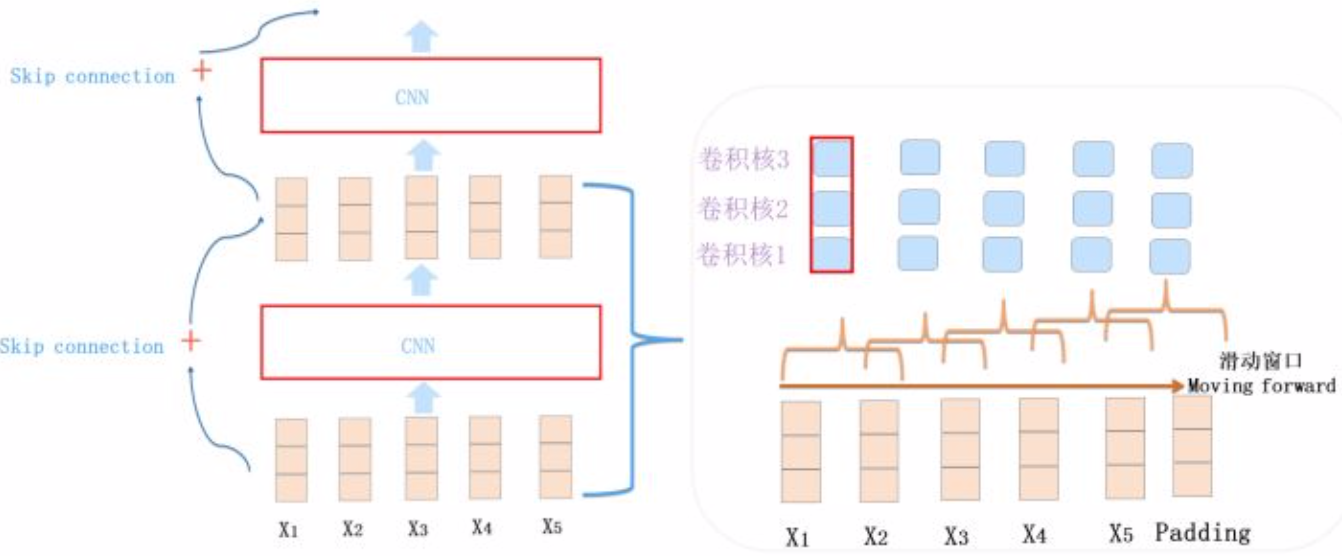
NLP领域主流的CNN
通常由 1-D 卷积层来叠加深度,使用 Skip Connection 来辅助优化,也可以引入 Dilated CNN 等手段。比如 ConvS2S 主体就是上图所示结构,Encoder 包含 15 个卷积层,卷积核 kernel size=3,覆盖输入长度为25。
TCN
Causal Convolutions
TCN 的两个原则:
- 输入和输出长度相等
- 不能泄露未来的信息
对应解决方法:
- 一维全卷积网络和Zero padding(kernel size - 1) 前者保证了隐藏层长度和输入层相同,后者保证了特征图每层大小相同。
- 使用因果卷积 t时刻的输出仅与时间t和前层中更早的元素有关。 (Waibel, Alex, Hanazawa, Toshiyuki, Hinton, Geoffrey, Shikano, Kiyohiro, and Lang, Kevin J. Phoneme recognition using time- delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(3), 1989.)
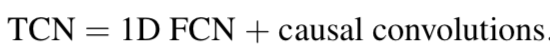
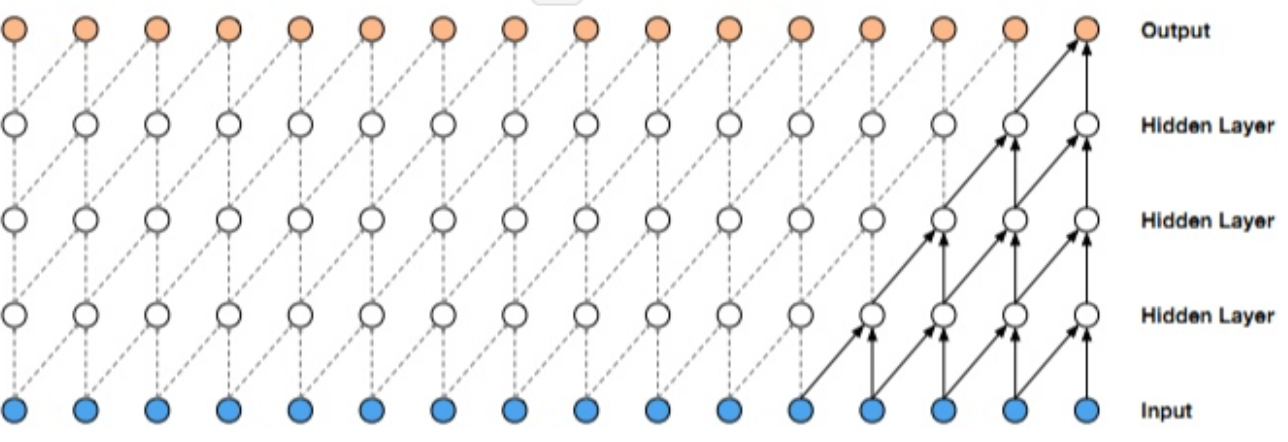
缺点: 上面的图片可以详细的解释因果卷积,但是问题就来,如果我要考虑很久之前的变量x,那么卷积层数就必须增加(自行体会)。。。卷积层数的增加就带来:梯度消失,训练复杂,拟合效果不好的问题,为了决绝这个问题,出现了扩展卷积(dilated)。 对于因果卷积,存在的一个问题是需要很多层或者很大的filter来增加卷积的感受野。扩大卷积(dilated convolution)是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。
Dilate Convolutions
感受野
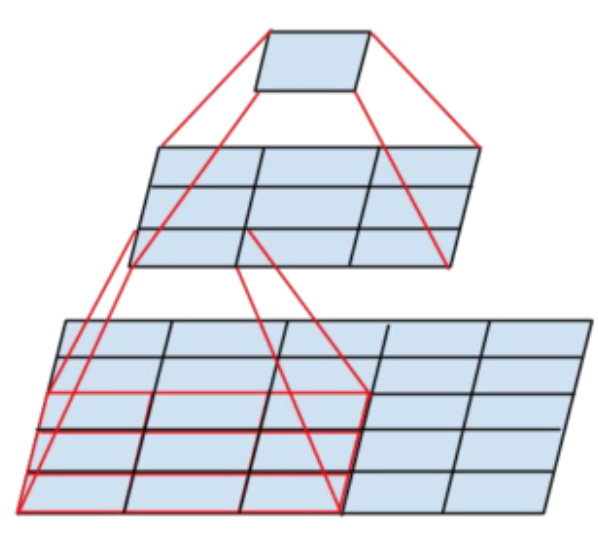 如果输出图像的每一个像素和输入图像的 $nn$ 的像素有关,那么久称输出图像的感受野为 $nn$。
如果输出图像的每一个像素和输入图像的 $nn$ 的像素有关,那么久称输出图像的感受野为 $nn$。
可以使用两层 $33$ 的卷积来模拟 $55$ 的卷积。这样可以节约参数,因为 $55$ 卷积的参数量为25,比 $33$ 卷积的参数量18还要多。这样做可以节约参数。
原方法: 输入 -> $5*5$ 卷积 -> 非线性
新方法: 输入 -> $33$ 卷积 -> 非线性 -> $33$ 卷积 -> 非线性
进一步继续这个思路,就是著名的Incepttion构架。根据Google实验,将卷积核拆分并加入更多的非线性,有可能进一步提升网络性能。
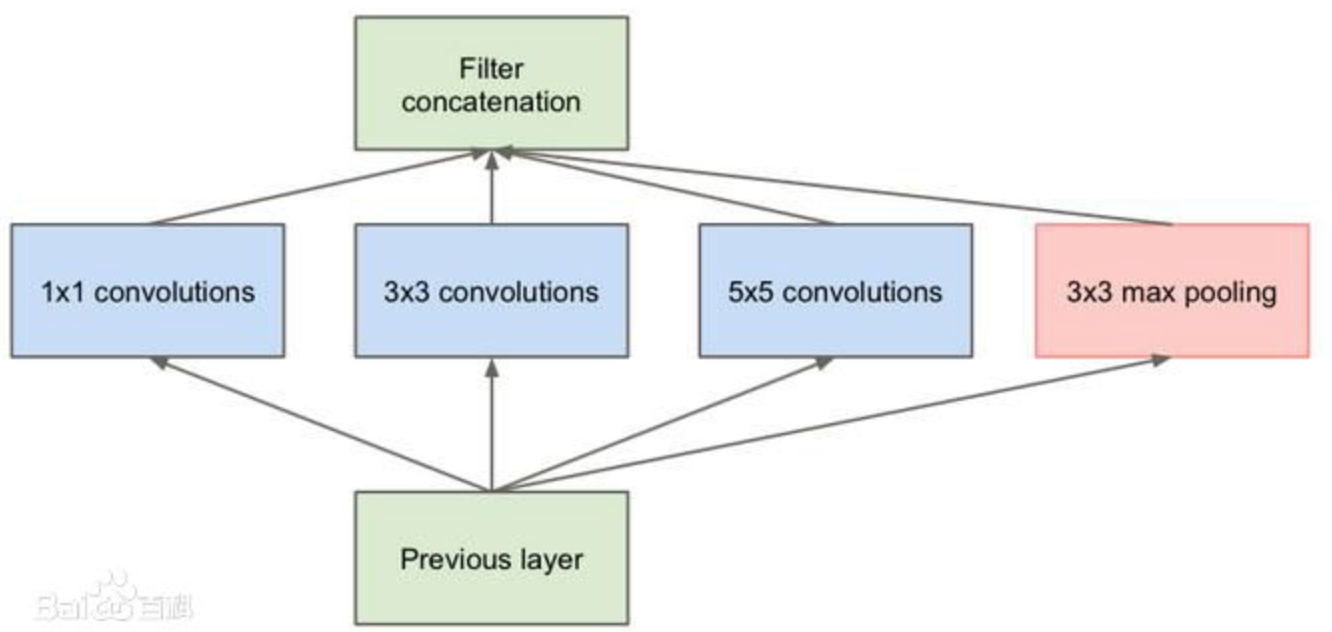
在传统深度学习网络构架中,如 AlexNet,会使用较大的卷积核,因为卷积核越大,感受野越大,看到的图像信息越多,有可能获得更好的特征。
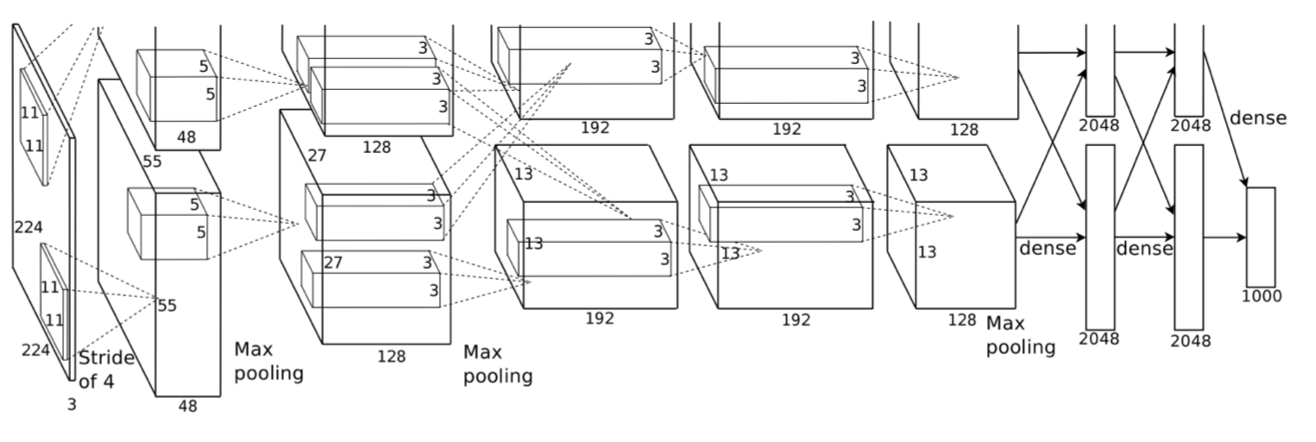
AlexNet总共包含8层,其中有5个卷积层和3个全连接层,有60M个参数,神经元个数为650k,分类数目为1000,LRN层出现在第一个和第二个卷积层后面,最大池化层出现在两个LRN层及最后一个卷积层后。
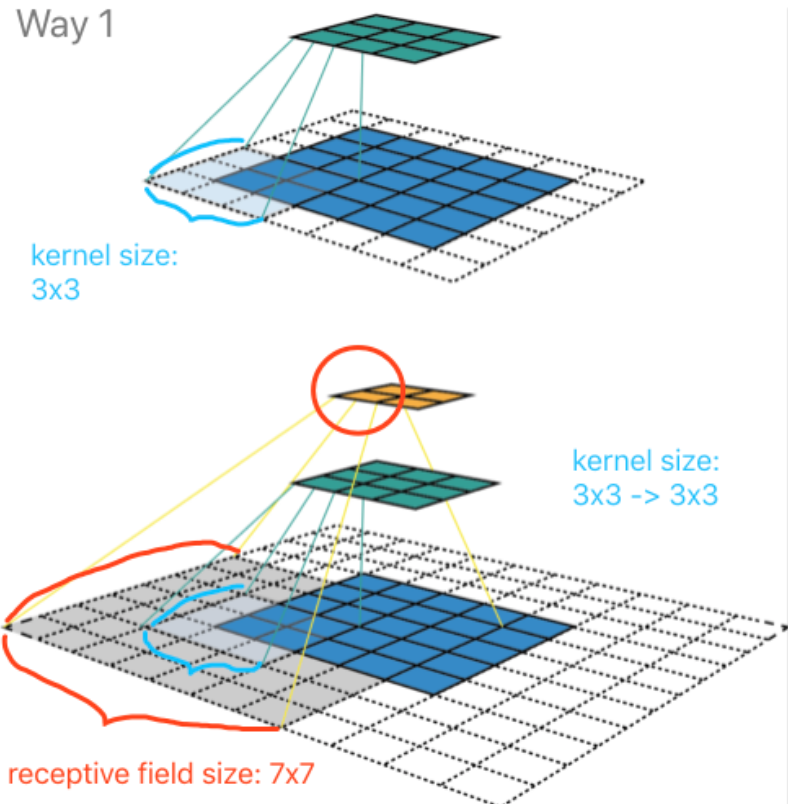
Way1 对应为通常的一种理解感受野的方式。在下方左侧的上图中,是在 5x5 的图像(蓝色)上做一个 3x3 卷积核的卷积计算操作,步长为2,padding 为1,所以输出为 3x3 的特征图(绿色)。那么该特征图上的每个特征(1x1)对应的感受野,就是 3x3。在下方左侧的下图中,是在上述基础上再加了一个完全一样的卷积层。对于经过第二层卷积后其上的一个特征(如红色圈)在上一层特征图上“感受”到 3x3 大小,该 3x3 大小的每个特征再映射回到图像上,就会发现由 7x7 个像素点与之关联,有所贡献。于是,就可以说第二层卷积后的特征其感受野大小是 7x7(需要自己画个图,好好数一数)。
扩展卷积
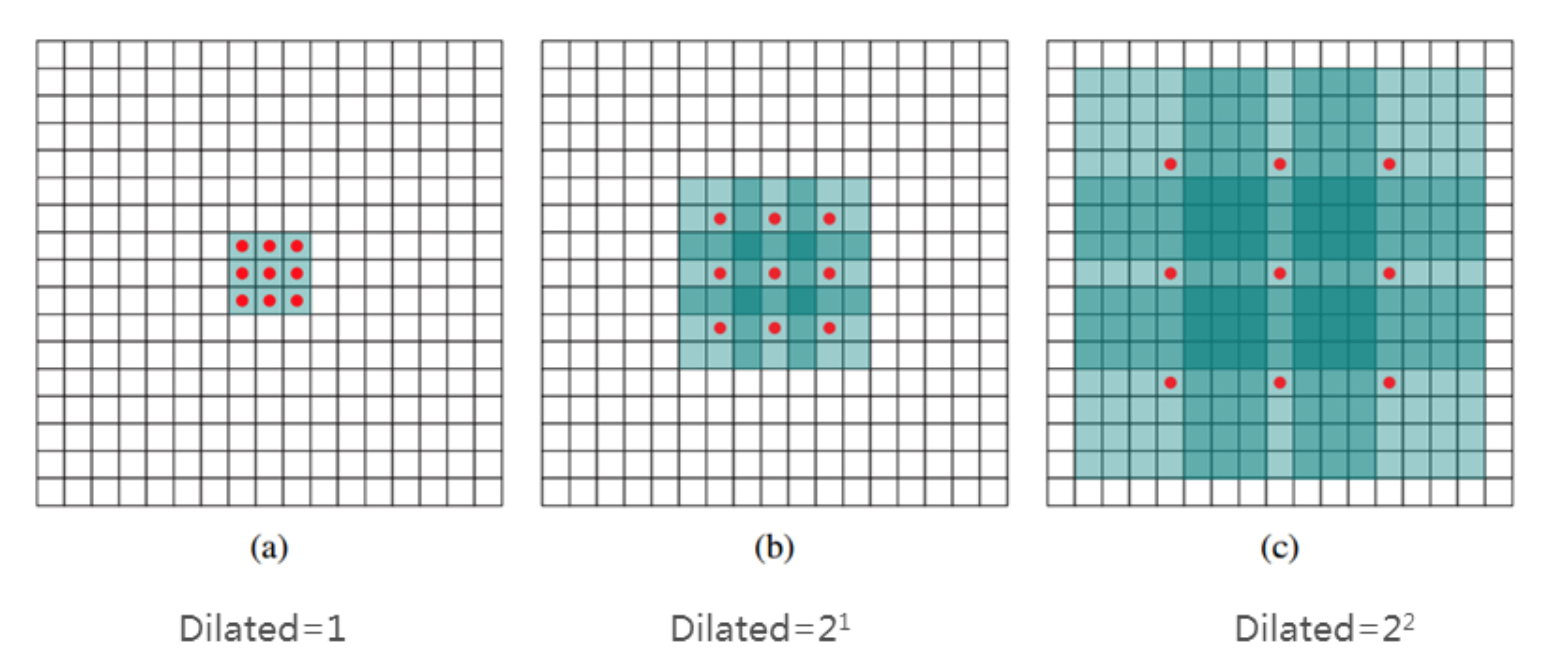
Dilated conv 在 ICLR 2016上提出。其主要作用是在不增加参数和模型复杂度的条件下,可以指数倍的扩大视觉野的大小。从下图中可以看出这一效果。蓝色的矩形表示视觉野。红色的小点表示 kernel。在图a中,kernel是 3*3,视觉野是 3*3,dilated=1;在图b中,kernel是3*3,但是视觉野是 7*7,dilated=2;在图c中,kernel是 3*3,但是视觉野是 15*15,dilated=4. 可以看出在dilated(扩展系数)扩大时,视觉野同样扩大。
 下面,我们使用1D的数据来详细看一下dilated。从下图可以看出,当dilated=2时,每一个输出,“看到了”3个输入(虽然其中2-1=1被忽略了)。当dilated=4时,“看到了”5个输入(4-1=3个被忽略了)
下面,我们使用1D的数据来详细看一下dilated。从下图可以看出,当dilated=2时,每一个输出,“看到了”3个输入(虽然其中2-1=1被忽略了)。当dilated=4时,“看到了”5个输入(4-1=3个被忽略了)
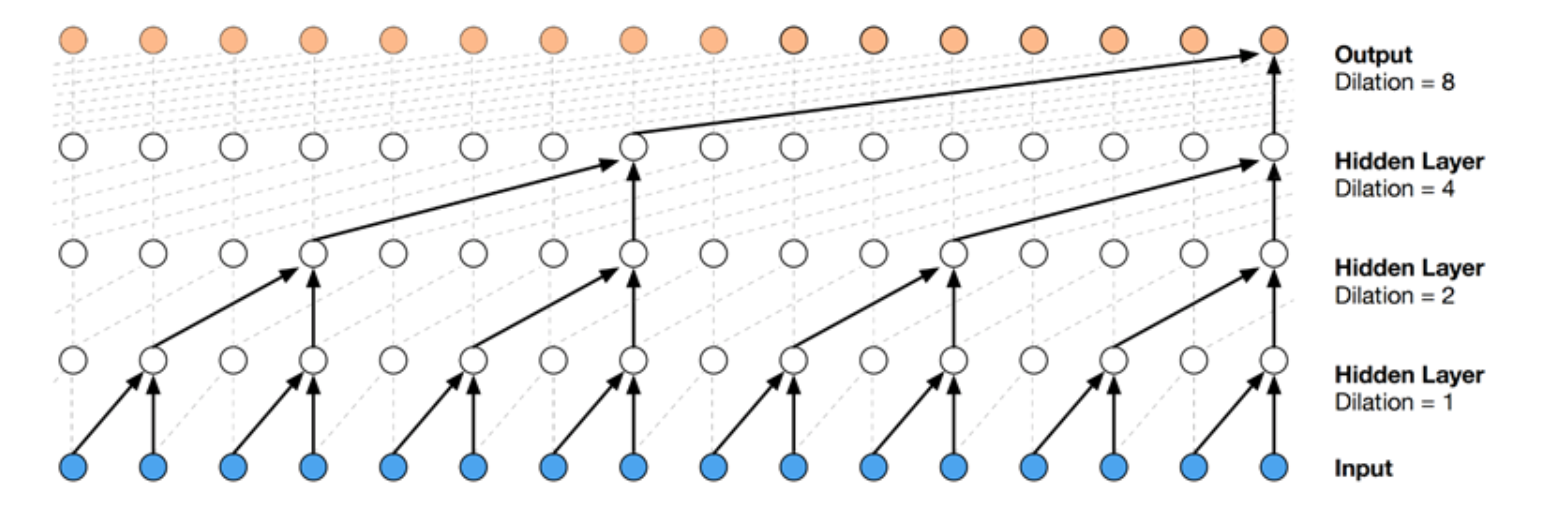 从上面的分析可以看出,dilated与stride非常相似。但dilated与stride可以等同吗?
答案是否定的。我们可以将dilated看成是kernel稀疏化的一种模式。而stride只是dilated的一种特例。根据不同任务,我们可以设计不同的稀疏模式。并不一定要求在宽上的稀疏个数等于长上的稀疏个数。
从上面的分析可以看出,dilated与stride非常相似。但dilated与stride可以等同吗?
答案是否定的。我们可以将dilated看成是kernel稀疏化的一种模式。而stride只是dilated的一种特例。根据不同任务,我们可以设计不同的稀疏模式。并不一定要求在宽上的稀疏个数等于长上的稀疏个数。
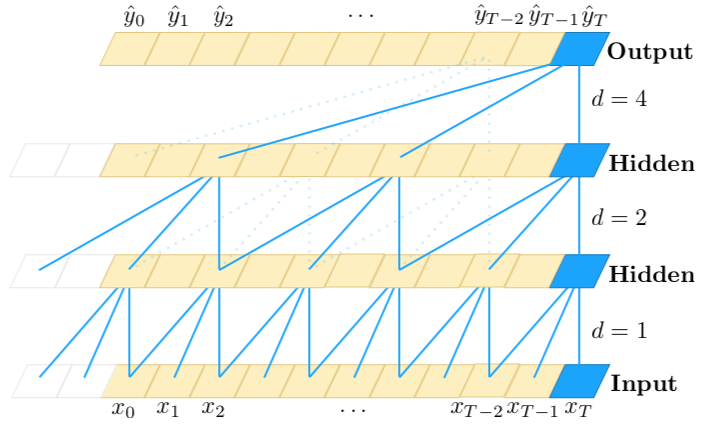 使用扩展卷积可以指数级增大卷积感受野。
使用扩展卷积可以指数级增大卷积感受野。
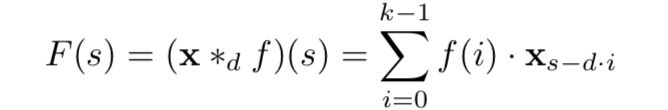 d为扩张因子。当d=1时,扩展卷积退化为正常卷积。使用大的扩展因子,可以使得顶层的输出表示更广泛的输入范围。
d为扩张因子。当d=1时,扩展卷积退化为正常卷积。使用大的扩展因子,可以使得顶层的输出表示更广泛的输入范围。
TCN给出了两种扩大感受野的方法:
- 选择更大的过滤器大小k
- 增大扩展因子d 这样得到的有效的感受野大小为(k-1)d。
Residual Convolutions
1*1卷积
最小的卷积核是 1*1 卷积核。表面上看,1*1 卷积核并不是真正的过滤器,它只是将图像的每个点都乘以1个权重,再加上一个偏置。通过 N 个 1*1 卷积神经元,只需要少量的参数,就可以将M张图片变成N张图片。1×1 卷积能够实现跨通道的交互和信息,1×1×F 的卷积在数学上就等价于多层感知机,F 是 filter 的数目,一个 filter 相当于就是对一张图片做一次卷积。
应用场景:
- 如需将图片分为N类,可以在最后用
1*1卷积层将M张图片变成N张图片,再通过全局池化变成N个数字,送入SoftMax层。 - 可以用
1*1卷积作为瓶颈层(bottleneck). 假设通道是256个,要求经过3*3卷积,最后输出通道也是256。两种实现方法: 第一种: 输入:256个通道 -> 256个3*3卷积神经元 -> 输出:256个通道 第二种: 输入: 256个通道 -> 64个1*1卷积神经元 -> 64个3*3卷积神经元 -> 256个1*1卷积神经元 -> 输出:256个通道 - 希望改变通道数过图片尺寸,简单的方法就是用 $1*1$ 卷积层。残差网络中就会用到这一点。
- 连续使用多个
1*1卷积层,可在图像的每个点上实现一个小型的MLP网络。
残差网络
深度学习的一大原则是,神经网络越深,效果往往越好。但极深的网络往往并不容易训练。梯度消失和梯度爆炸曾是困扰研究人员的难题。2015年,微软亚洲研究院(MSRA)公布了152层残差网络,ResNet,论文为《Deep Residual Learning for Image Recognition》,成为了深度网络构架的重要突破。2016年进行了改进(http://arxiv.org/abs/1603.05027),MSRA成功训练了深度为1000层的网络,并实现了更低的错误率。
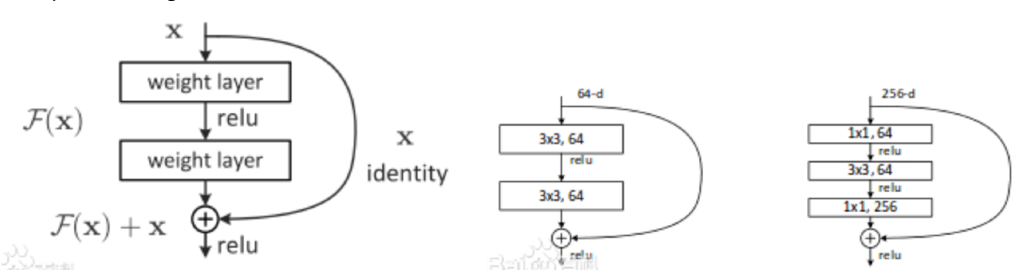 经实际测试,每次跳过 2 层网络可能实现更好的性能。因为2层网络可提供更多的非线性,拟合更复杂的 F(x)。左一是残差网络的基本模组(block)。实际做法如左二所示。右一为加入瓶颈层的残差网络。
在 2016 年的后续论文中,《Identity Mappings in Deep Residual Network》研究人员测试了多种网络的组合,包括BN层和非线性层的位置调整。
经实际测试,每次跳过 2 层网络可能实现更好的性能。因为2层网络可提供更多的非线性,拟合更复杂的 F(x)。左一是残差网络的基本模组(block)。实际做法如左二所示。右一为加入瓶颈层的残差网络。
在 2016 年的后续论文中,《Identity Mappings in Deep Residual Network》研究人员测试了多种网络的组合,包括BN层和非线性层的位置调整。
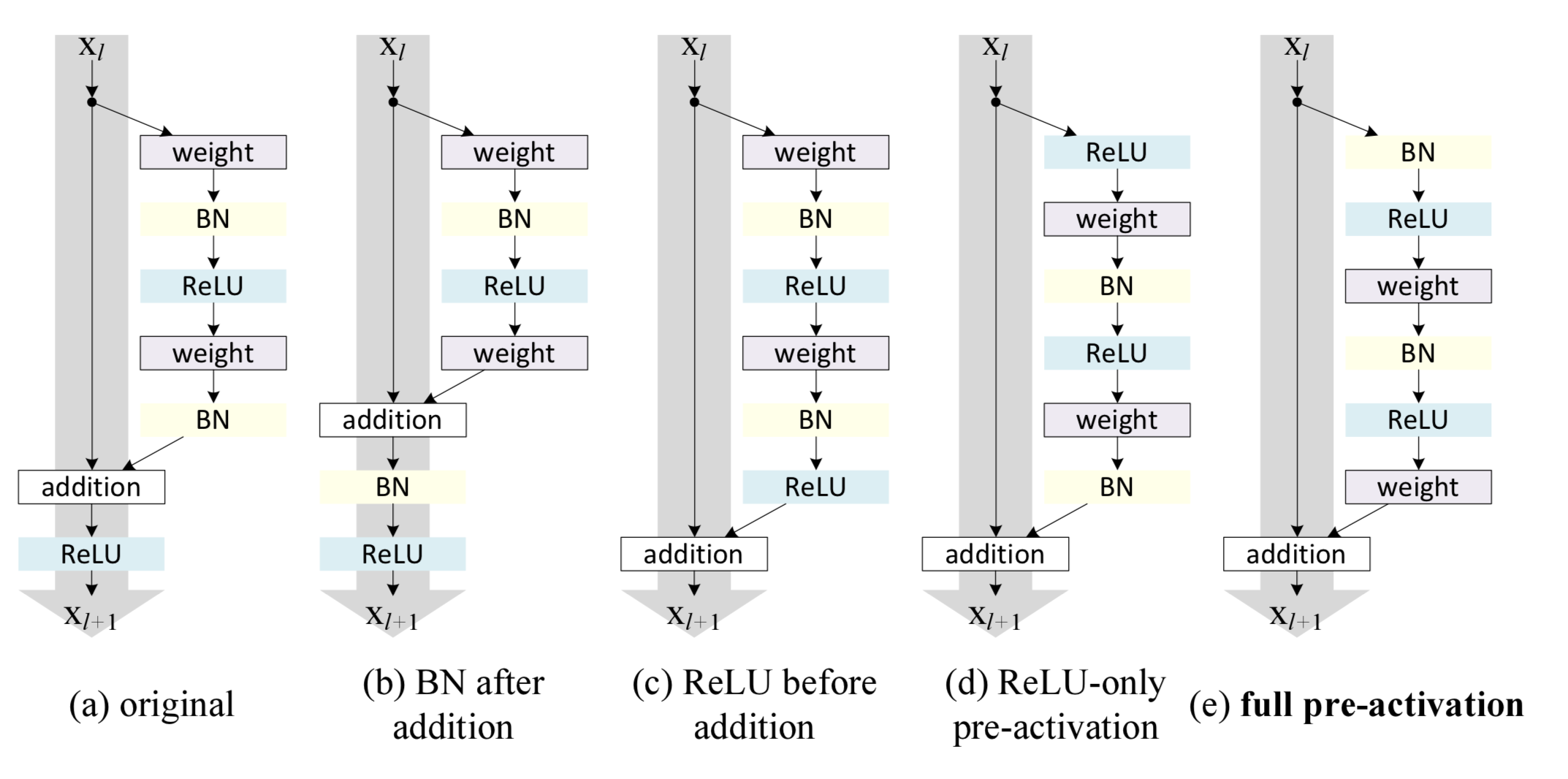 e的效果最好,错误率最低,左通道上没有ReLU层,实现了信息的完全畅通。
c架构的问题在于,它将ReLU放在了有通道的最后。由于ReLU的输出永远大于等于0,这对于网络的表达能力是有害的。
而d和e的区别在于BN层的位置。事实上,BN层最适宜放在非线性激活函数前边。e无疑满足了多有要求。
e的效果最好,错误率最低,左通道上没有ReLU层,实现了信息的完全畅通。
c架构的问题在于,它将ReLU放在了有通道的最后。由于ReLU的输出永远大于等于0,这对于网络的表达能力是有害的。
而d和e的区别在于BN层的位置。事实上,BN层最适宜放在非线性激活函数前边。e无疑满足了多有要求。
为了保证TCN的稳定,使用残差网络。
对依赖2^12大小的感受野和高维的输入序列进行预测,网络可能会达到12层,每层包含多个特征提取器。会出现梯度消失等问题。这里使用残差模块代替卷积层。
残差模块包含:两层扩展卷积,线性矫正单元 Relu,权重归一化优化方法(用于filter),Dropout。
在标准的 ResNet 中,输入直接添加到输出中。而在 TCN 中,输入和输出可能具有不同的宽度,因此引入 1*1 卷积,确保接受相同形状的张量。
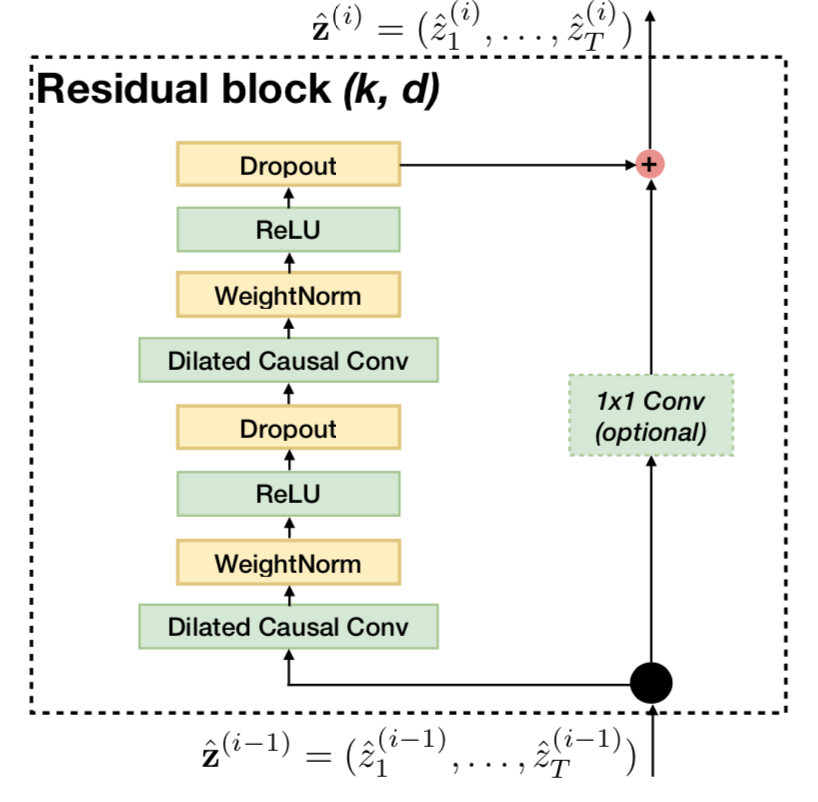
TCN 的结构
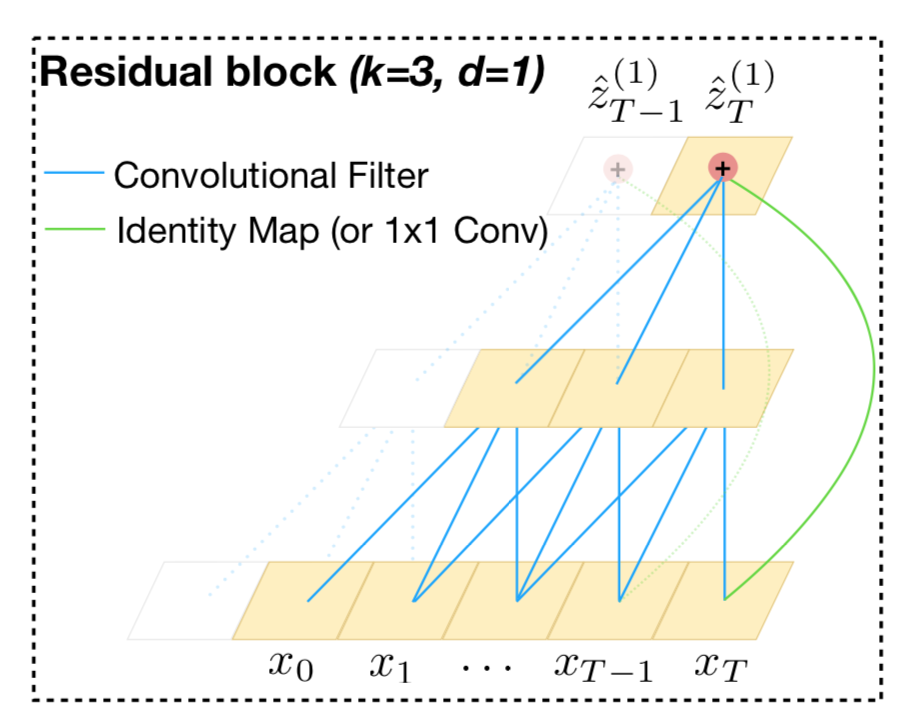 从五个方面对TCN进行讨论:
从五个方面对TCN进行讨论:
- Parallelism
- Flexible receptive field size
- Stable gradients
- Low memory requirement for training
- Variable length inputs
并行性。在RNN中,对以后的时间步的预测必须等待它们的前辈完成,卷积可以并行进行,因为在每个层中使用相同的过滤器。因此,在训练和评估中,一个长的输入序列可以在TCN中作为一个整体进行处理,而不是像在RNN中那样按顺序进行处理。 灵活的接收字段大小。TCN可以通过多种方式改变其接收场的大小。例如,使用更大的膨胀系数或增大滤波器的大小来叠加更多的膨胀(因果)卷积层都是可行的选择(可能有不同的解释)。因此,TCN能够更好地控制模型的内存大小,并且易于适应不同的域。 NN的并行计算能力,那是非常强的,这其实很好理解。我们考虑单层卷积层,首先对于某个卷积核来说,每个滑动窗口位置之间没有依赖关系,所以完全可以并行计算;另外,不同的卷积核之间也没什么相互影响,所以也可以并行计算。CNN的并行度是非常自由也非常高的,这是CNN的一个非常好的优点。
稳定的坡度。与循环体系结构不同,TCN的反向传播路径不同于序列的时间方向。因此,TCN避免了爆炸/消失梯度的问题,这是RNN的一个主要问题(并导致LSTM、GRU、HF-RNN(Martens&Sutskever,2011)等的发展)。
训练所需的内存不足。尤其是在长输入序列的情况下,LSTM和GRU可以很容易地使用大量内存来存储其多个单元门的部分结果。然而,在TCN中,过滤器是跨层共享的,而反向传播路径仅取决于网络深度。因此,在实践中,我们发现门控RNN可能比TCN消耗更多的内存。
可变长度输入。与RNN一样,TCN也可以通过滑动一维卷积核来获取任意长度的输入,RNN以循环的方式对可变长度的输入进行建模。这意味着对于任意长度的序列数据,TCN可以作为RNN的替代品。
实验
测试集
The Adding Problem
这一任务是一个回归问题。用来验证循环神经网络在学习长期依赖方面的能力。Adding Problem输入的是两个向量,这两个向量具有相同的长度T。其中一个称为出具序列,这个序列包含T个随机生成的数字,这些数字在[0,1]之间,并且服从统一分布。另一个被称为指示序列,这个序列也包含T个数字,除了两个位置的值为1,其余都是0,这两个位置是随机的。Adding Problem的目标输出是数据序列中两个数值之和,这两个数值在指示序列中对应的位置值为1。
 在这个序列中第一个时刻输入的为[0.4, 0],第二个时刻输入的序列为[0.6, 0],以此类推,一共有T个时刻。
最简单的策略就是不管输出什么值一直预测输出为1,这样能得到一个均方误差MSE(Mean Squared Error)的期望为0.1767。这是一个基准,需要所有模型获得比这个基准更低的错误。
随着序列长度的增加,Adding Problem变得越来越难处理。首先序列中第一个值和第二个值之间的距离变得越来越远,增加了学习长期依赖的难度。其次,序列中会有更多不相关的数字,这会给模型学习序列的特征带来带来更大的干扰。解决Adding Problem需要神经网络记住两个值的同时忽略大量无效数字。
在这个序列中第一个时刻输入的为[0.4, 0],第二个时刻输入的序列为[0.6, 0],以此类推,一共有T个时刻。
最简单的策略就是不管输出什么值一直预测输出为1,这样能得到一个均方误差MSE(Mean Squared Error)的期望为0.1767。这是一个基准,需要所有模型获得比这个基准更低的错误。
随着序列长度的增加,Adding Problem变得越来越难处理。首先序列中第一个值和第二个值之间的距离变得越来越远,增加了学习长期依赖的难度。其次,序列中会有更多不相关的数字,这会给模型学习序列的特征带来带来更大的干扰。解决Adding Problem需要神经网络记住两个值的同时忽略大量无效数字。
MNIST序列分类任务
MNIST数据集是一个手写数字识别数据集,包含60000张用于训练的图像和10000张用于测试的图像。每张图像包含一个0到9的数字,将这些图像分为10类。MNIST的图像是灰度图,而且长和宽都是28。为了将这个任务转化为序列任务,将二维图像转化为一个序列,在这个任务中,每一个时刻输入一个像素。从左到右,从上到下将图像的像素一一读入序列中,那么序列长度为784。P-MNIST数据集,是将图片的像素转化为序列时,依次随机读取像素点,每张图片使用相同的随机读取方式。由于MNIST中包含大量的局部信息,序列长度达到784,所以MNIST足以用于验证网络的学习序列长度依赖和捕获局部特征的能力。
Copy memory
每个输入序列的长度为t+20,其中前10个值是1到8之间的随机整数。模型应该在T步骤之后记住它们。 序列的其余部分都是零,除了序列中的最后11个条目,该条目以9开头,表示模型应该开始输出其存储的值。 除了最后10个条目外,该模型预计在每个时间步都会给出零输出,在这里,它应该按照在序列开始时看到的相同顺序生成(复制)10个值。 其目的是在每个时间步最小化类别预测的平均交叉熵。
JSB Chorales and Nottingham
JSB 是一个复调音乐集,由382个由四部分组成的协调合唱团组成。每个输入都是一个元素序列。每个元素都是一个88位二进制代码,对应于钢琴上的88个键,1表示在给定时间按下的键。诺丁汉是一个复调音乐集,基于1200个英国和美国民歌的收集,并远远大于JSB合唱团。JSB Chorales和Nottingham已被用于多次重复序列建模的实证研究。两个任务的性能都是用负对数似然(nll)来衡量的。
PennTreebank(PTB)
这是一个字符级语言模型,用来预测文本的下一个字符,而不是下一个单词。尽管相同条件下,字符集语言模型的预测能力比单词的模型预测能力稍差。字符集语言模型的预测的任务是衡量网络的预测性能。PTB包括训练集,验证集和测试集。其中训练集包括5059k个字符,验证集396个字符,测试集446k个字符。训练过程中训练集被分割成长度为100的子串,无需其他与处理。
Wikitext-103
维基文本-103是PTB的110倍大,其词汇量约为268K。数据集包含28K篇维基百科文章(约1.03亿字)用于训练,60篇文章(约218K字)用于验证,60篇文章(246K字)用于测试。这是一个比PTB更具代表性和现实性的数据集,具有更大的词汇表,包括许多罕见的单词。
LAMBADA
LAMBADA是一个常用于阅读理解的数据集,包括从小说中提取的10K段,平均4.6个句子作为上下文,1个目标句子,其最后一个词是要被预测的。LAMBADA的训练数据包括2662部小说的全文,字数超过2亿,词汇量大约是93K。数据集是为了让一个人在给出上下文句子时能够很容易地猜测漏掉的单词。研究结果表明,一个模型能够更好地从更长更广的上下文中捕获信息。
text8
text8数据集用于字符级语言建模。text8大约是ptb的20倍,来自维基百科的大约100万个字符(90M用于训练,5M用于验证,5M用于测试)。
实验
The adding problem
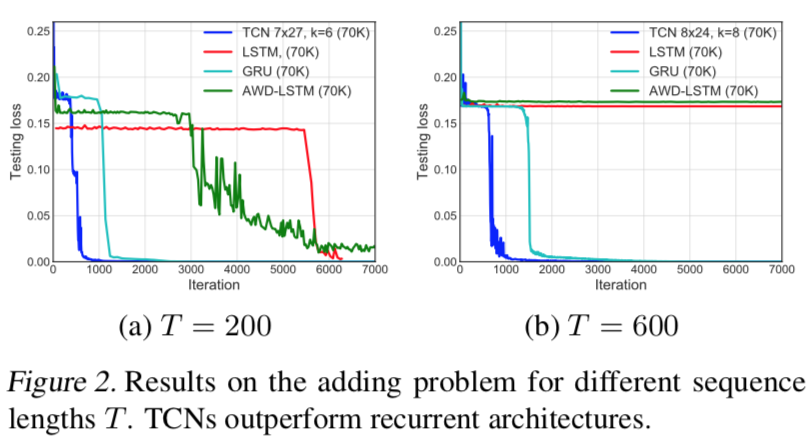 T=200和600,收敛结果如图所示。所有的模型都有大约70K的参数。TCN迅速收敛到一个几乎完美的解决方案(即MSE接近0)。GRUS的表现也不错,尽管其收敛速度比TCN慢。LSTM和Vanilla RNN表现明显较差。
T=200和600,收敛结果如图所示。所有的模型都有大约70K的参数。TCN迅速收敛到一个几乎完美的解决方案(即MSE接近0)。GRUS的表现也不错,尽管其收敛速度比TCN慢。LSTM和Vanilla RNN表现明显较差。
Sequential MNIST and P-MNIST
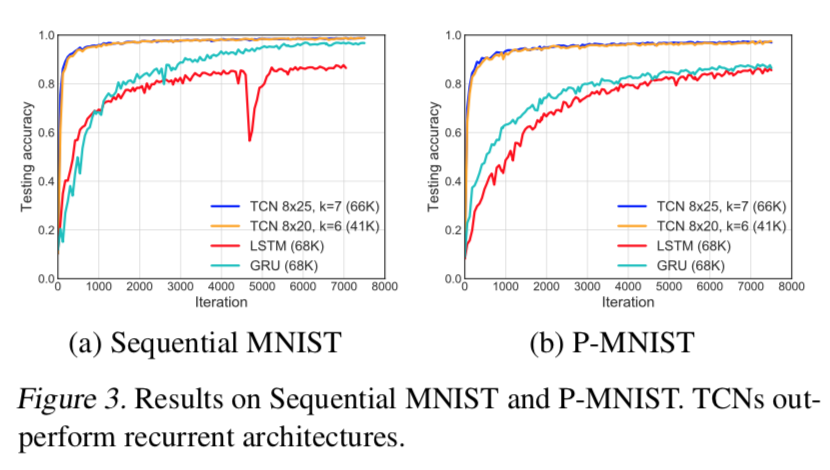 在MNIST序列任务上的收敛结果,运行超过10个epochs ,如图所示。所有的模型都有大约70k个参数。对于这两个问题,无论是在收敛性方面还是在任务的最终准确性方面,TCN都明显优于循环体系结构。
在MNIST序列任务上的收敛结果,运行超过10个epochs ,如图所示。所有的模型都有大约70k个参数。对于这两个问题,无论是在收敛性方面还是在任务的最终准确性方面,TCN都明显优于循环体系结构。
Copy memory
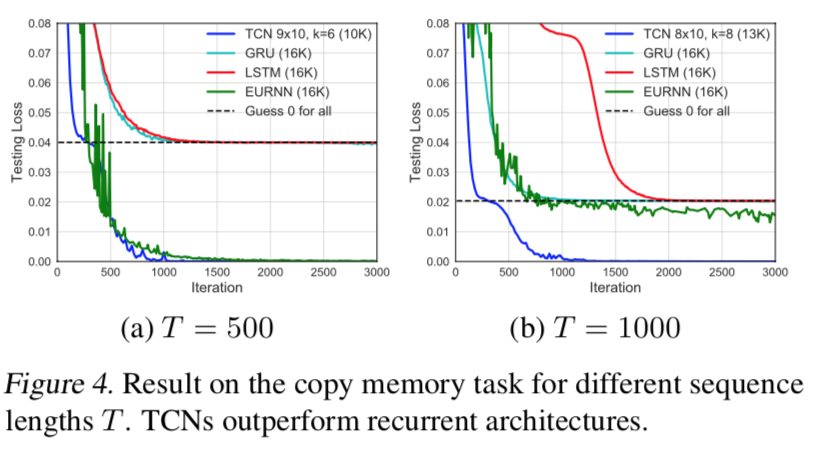 Copy memory任务的收敛结果如图所示。TCN很快收敛到正确的答案,而LSTMS和GRU与预测所有零的损失几乎相同。在这种情况下,我们还将其与最近提出的EURNN进行了比较,此模型在这项任务上表现良好。虽然TCN和EURNN在序列长度T=500时都表现良好,但TCN在T=1000和更长时间内(在损失和收敛速度方面)有明显的优势。
Copy memory任务的收敛结果如图所示。TCN很快收敛到正确的答案,而LSTMS和GRU与预测所有零的损失几乎相同。在这种情况下,我们还将其与最近提出的EURNN进行了比较,此模型在这项任务上表现良好。虽然TCN和EURNN在序列长度T=500时都表现良好,但TCN在T=1000和更长时间内(在损失和收敛速度方面)有明显的优势。
Polyphonic Music and Language Modeling
我们讨论复调音乐建模、字符级语言建模和单词级语言建模的结果。
 Polyphonic music
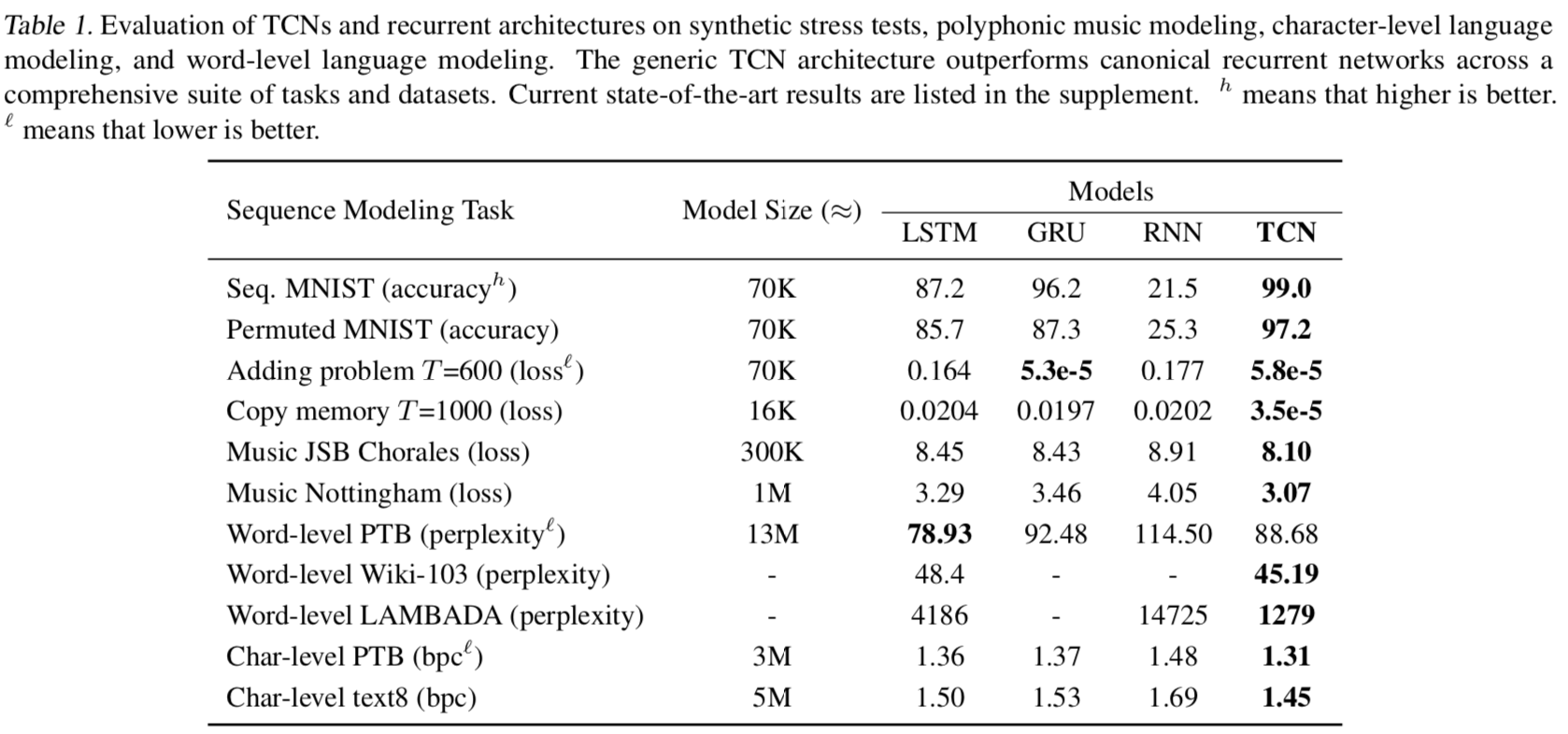
在Nottingham和JSB Chorales上,几乎没有调优的TCN在很大程度上优于循环网络模型,甚至优于某些增强的循环架构,例如HF-RNN(BoulangerLewandowski等,2012)和Diagonal RNN(Subakan& Smaragdis,2017)。但是,如Deep Belief Net LSTM模型表现更好(Vohra等,2015);我们认为这可能是由于数据集相对较小,因此正确的正则化方法或生成建模程序可以显着提高性能。
Polyphonic music
在Nottingham和JSB Chorales上,几乎没有调优的TCN在很大程度上优于循环网络模型,甚至优于某些增强的循环架构,例如HF-RNN(BoulangerLewandowski等,2012)和Diagonal RNN(Subakan& Smaragdis,2017)。但是,如Deep Belief Net LSTM模型表现更好(Vohra等,2015);我们认为这可能是由于数据集相对较小,因此正确的正则化方法或生成建模程序可以显着提高性能。
Word-level language modeling
语言建模仍然是循环网络的主要应用之一,最近的许多工作都致力于为此任务优化LSTM(Krueger等人,2017年;Merity等人,2017年)。我们的实现遵循标准实践,将TCN和RNN的编码器和解码器层的权重联系起来(Press&Wolf,2016),这显著减少了模型中的参数数量。使用SGD进行训练,并在验证准确度达到高峰时将tcn和rnns的学习速率是0.5。在较小的ptb语料库上,tcn优于gru和vanilla rnn。然而,在更大的wikitext-103语料库和lambada数据集上,在没有任何超参数搜索的情况下,TCN优于Grave等人的LSTM结果,实现了更低的困惑。
Character-level language modeling.
在字符级语言建模(ptb和text8,以每字符位度量的精度)上,通用TCN优于常规LSTM和GRU以及规范稳定LSTM等方法(Krueger和Memisevic,2015年)。(现有的特殊化架构优于所有这些架构,请参阅补充部分。)
总结
TCN 形式简洁:使用卷积形式(convolution) 适用于序列模型:因果卷积 (causal convolutions) 对历史有记忆:扩展卷积(dilated convolutions)+残差模块(residual block) 输入输出维度保持一致:全卷积网络(fully-convolutional network)
缺点:
- 合成数据任务,很难应用到 NLP 领域
- 比较基准低
- 没有使用NLP领域中有效的门控机制(附录中有提到,但是效果不好)
利用 Dilated CNN 拓展单层卷积层的输入覆盖长度,利用全卷积层堆叠层深,使用 Skip Connection 辅助优化,引入 Casual CNN 让网络结构看不到T时间步后的数据。不过 TCN 的实验做得有两个明显问题:一个问题是任务除了语言模型外都不是典型的NLP任务,而是合成数据任务,所以论文结论很难直接说就适合 NLP 领域;另外一点,它用来进行效果比较的对比方法,没有用当时效果很好的模型来对比,比较基准低。所以TCN的模型效果说服力不太够。
参考文献
《An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling》

