
Style Transfer in Text Exploration and Evaluation
Abstract
2 main problems in Style Transfer:
- Lack of parallel data
- Model learn from non-parallel data
- Learn separate content representations and style representations using adversarial networks.
- Lack of reliable metrics
- propose two novel evaluation metrics that measure two aspects of style transfer: transfer strength and content preservation
Contribution
- Compose a dataset of paper-news titles to facilitate the research in language style transfer
- Propose two general evaluation metrics for style transfer, which considers both transfer strength and content preservation. The evaluation metric is highly correlated to the human evaluation.
Model
(both only contains the content information)
multi-encoder
- The multi-decoder model uses different decoders, one for each style, to generate texts in the corresponding style.
困难在于encoder如何生成只含有content信息的representation,不包含原来的style信息(有点不理解是为什么…)
设置目标函数用adversarial network 处理post的style分类:目标是 to separate the content representation from the style. 这里有两个loss: 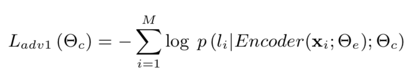 to minimizes the negative log probability of the style labels in the training data. (这里(theta_c) 是 predict style的分类器的参数)
to minimizes the negative log probability of the style labels in the training data. (这里(theta_c) 是 predict style的分类器的参数) 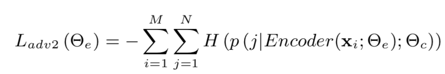 by maximize the entropy (minimize the negative entropy) of the predicted style labels, make the classifier unable to identify the style of (x)
by maximize the entropy (minimize the negative entropy) of the predicted style labels, make the classifier unable to identify the style of (x)
然后,对于多个不同style的decoder: 还有一个传统的loss, 使得输入输出的语义更相似(这里我也有点不太认同) 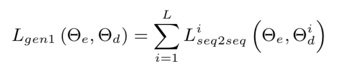
所以这个multi-encoder的总体loss为: 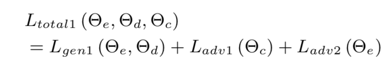
style embedding
与上述模型类似,只是在参数中加入了所有style categoris的embeddings的矩阵(Ein R^{N*d_s}) (N) for the number of styles (d_s) for the dim of style embeddings
这部分的Loss为: 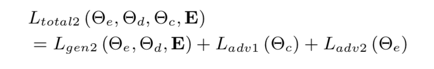
- The style-embedding model learns style embeddings addition to the content representations.
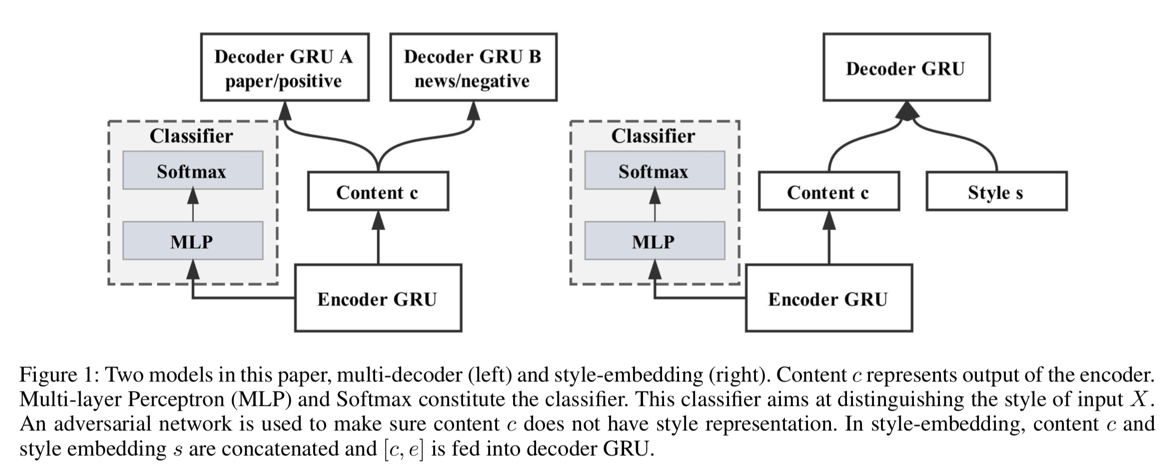
2 models
Metrics:
- Transfer Strength
- evaluates whether the style is transferred to target style(用LSTM-sigmoid构建一个分类器,通过acc衡量)
- Content Preservation
- evaluate the similarity between source text and target text
Dataset
- paper-news title dataset
- positive-negative review dataset
Acquisition:
Model很直观,只是对于adversarial 的思路还是不太理解,有一些不理解的点标红了 (感觉没有体现出Contribution中说的parallel数据的特点)

